数组
创建数组
数组字面量
1、字面量创建:
|
|
数组字面量写法:一系列的值,用逗号分隔,用方括号括起来。
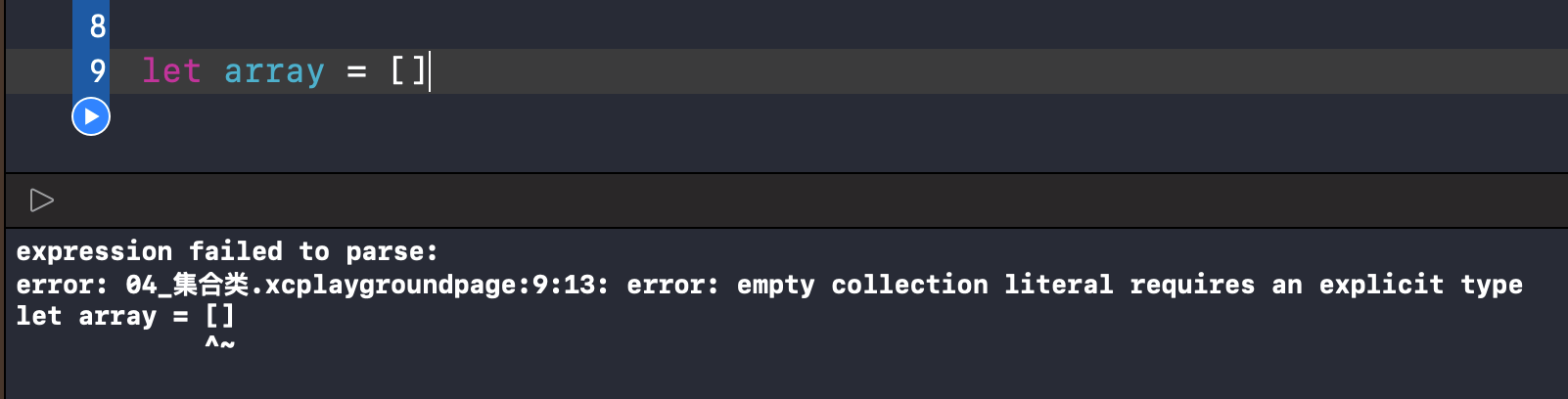
2、字面量创建空数组:
|
|
⚠️注意:创建空数组必须携带类型信息,否则编译不通过。
3、如果内容已经提供了类型信息,则可以通过空数组字面量来创建一个空数组:
|
|
提供类型信息的情况包括:
- 作为函数的实际参数;
- 已经分类了的变量或常量;
初始化器
使用初始化器有两种方式:
1、[类型]()
|
|
2、Array<类型>()
|
|
初始化器参数
|
|
|
|
|
|
|
|
数组遍历与索引
For-In
1、遍历
|
|
打印结果:
|
|
2、使用 break 跳出循环。
|
|
打印结果中只有0、1、2:
|
|
3、使用 continue 跳过循环。
|
|
打印结果中没有3:
|
|
forEach
1、遍历。
|
|
打印结果:
|
|
2、无法使用 break 或 continue 跳出或者跳过循环。
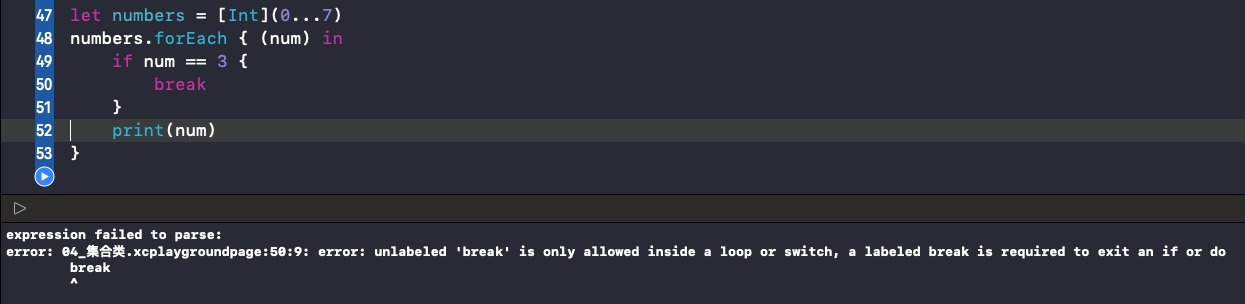
3、使用 return 只能退出当前一次循环的执行体,效果等同于 For-in 中使用 continue。
|
|
打印结果中没有3:
|
|
enumerated
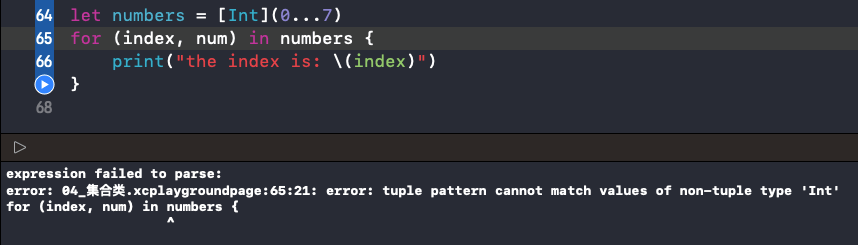
可以实现同时得到索引和值。
|
|
打印结果:
|
|
想要同时得到索引和值,必须使用 enumerated(),否则会报错。
Iterator
Iterator:迭代器。
|
|
打印结果:
|
|
索引
startIndex:返回第一个元素的位置,对于数组来说,永远都是0。
|
|
endIndex:返回最后一个元素 索引值+1 的位置,对于数组来说,等同于count。
|
|
对于空数组,startIndex 等于 endIndex。
indices:获取数组的索引区间。
|
|
打印结果:
|
|
数组的查找操作
判断是否包含指定元素
contains(_:):判断数组是否包含给定元素。
|
|
contains(where:):判断数组是否包含符合给定条件的元素。
|
|
判断所有元素符合某个条件
allSatisfy(_:):判断数组的每一个元素都符合给定的条件。
|
|
打印结果:
|
|
查找元素
first:返回数组第一个元素,如果数组为空,返回 nil。
|
|
last:返回数组最后一个元素,如果数组为空,返回 nil。
|
|
first(where:):返回数组第一个符合给定条件的元素。
|
|
last(where):返回数组最后一个符合给定条件的元素。
|
|
查找索引
firstIndex(of:):返回给定元素在数组中出现的第一个位置。
|
|
lastIndex(of:):返回给定元素在数组中出现的最后一个位置。
|
|
firstIndex(where:):返回符合条件的第一个元素的位置。
|
|
lastIndex(where:):返回符合条件的最后一个元素的位置。
|
|
查找最大最小元素
min():返回数组中最小的元素。
|
|
max():返回数组中最大的元素。
|
|
min(by:):利用给定的方式比较元素并返回数组中最小的元素。
|
|
max(by:):利用给定的方式比较元素并返回数组中最大的元素。
|
|
数组添加和删除
在末尾添加
append(_:):在末尾添加一个元素。
|
|
append(contentsOf:):在末尾添加多个元素。
|
|
在任意位置插入
insert(_:at:):在指定位置插入一个元素。
|
|
insert(contentOf:at:):在指定位置插入多个元素。
|
|
字符串也是集合
字符串也是集合(Collection),Element(元素)是字符(Character)类型。
|
|
移除单个元素
remove(at:):移除并返回指定位置的一个元素。
|
|
removeFirst():移除并返回数组的第一个元素。
|
|
removeLast():移除并返回数组的最后一个元素。
|
|
popLast:移除并返回数组的最后一个元素(Optional),如果数组为空返回nil。
|
|
|
|
移除多个元素
removeFirst(:):移除数组前面多个元素。
|
|
removeLast(:):移除数组后面多个元素。
|
|
removeSubrange(_:):移除数组中给定范围的元素。
|
|
removeAll():移除数组所有元素,数组容量置为0。
|
|
removeAll(keepingCapacity:):移除数组所有元素,保留数组容量。
|
|
ArraySlice
ArraySlice 是数组或者其它 ArraySlice 的一段连续切片,和原数组共享内存。当要改变 ArraySlice 的时候,ArraySlice 会 copy 出来,形成单独内存。
ArraySlice 拥有和 Array 基本完全类似的方法。
通过 Drop 得到 ArraySlice
dropFirst(:):“移除”原数组前面指定个数的元素得到一个 ArraySlice。
移除前面指定个数的元素,每次操作得到一个新的 ArraySlice:
|
|
移除后面指定个数的元素,每次操作得到一个新的 ArraySlice:
|
|
通过 prefix 得到 ArraySlice
prefix():获取数组前面指定个数的元素组成 ArraySlice。
|
|
prefix(upTo:):获取数组到指定位置(不包含指定位置)前面的元素组成 ArraySlice。
|
|
prefix(through:):获取数组到指定位置(包含指定位置)前面的元素组成 ArraySlice。
|
|
prefix(while:):获取数组前面符合条件的元素(到第一个不符合条件的元素截止)组成的 ArraySlice。
|
|
通过 suffix 得到 ArraySlice
suffix():获取数组后面指定个数的元素组成的 ArraySlice。
|
|
suffix(from:):获取数组从指定位置到结尾(包含指定位置)的元素组成的 ArraySlice。
|
|
通过 Range 得到 ArraySlice
可以通过对数组下标指定 Range 获取 ArraySlice,可以使用闭区间、半开半闭区间、单侧区间截取数组获得 ArraySlice,也可以用...来获取整个数组组成的 ArraySlice。
|
|
ArraySlice 转为 Array
ArraySlice 无法直接复制给一个 Array 的常量或变量,需要使用 Array(slice) 方法转成 Array 类型。
|
|

ArraySlice 和原 Array 相互独立
ArraySlice 和原 Array 是相互独立的,它们添加删除元素不会影响对方。
|
|
重排操作
数组元素的随机化
shuffle():在原数组上将数组元素打乱,只能作用在数组变量上。
|
|
shuffled():返回原数组的随机化数组,可以作用在数组变量和常量上。
|
|
数组的逆序
reverse():在原数组上将数组逆序,只能作用在数组变量上。
|
|
reversed():返回原数组的逆序“集合表示”,可以作用在数组变量和常量上,该方法不会分配新内存空间。
|
|
数组的分组
partition(by belongsInSecondPartition: (Element) throws -> Bool) rethrows -> Int:将数组以某个条件分组,数组前半部分都是不符合条件的元素,数组后半部分都是符合条件的元素。
|
|
数组的排序
sort:在原数组上将元素排序,只能作用于数组变量。
|
|
sorted():返回原数组的排序结果数组,可以作用在数组变量和常量上。
|
|
交换数组两个元素
swapAt(_ i: Int, _ j: Int):交换指定位置的两个元素。
|
|
拼接操作
字符串数组拼接
joined():拼接字符串数组里的所有元素为一个字符串。
|
|
joined(separator):以给定的分隔符拼接字符串数组里的所有元素为一个字符串。
|
|
元素为 Sequence 数组的拼接
joined():拼接数组里的所有元素为一个更大的 Sequence。
|
|
打印结果:
|
|
joined(separator:):以给定的分隔符拼接数组里的所有元素为一个更大的Sequence。
|
|
探秘数组
阅读源码:
- 先看顶层设计,再看底层源码是怎么符合顶层设计的。
- 从关键的调用链开始,找到关键方法,再看关键方法底层又调用到了哪些方法。
数组的协议结构
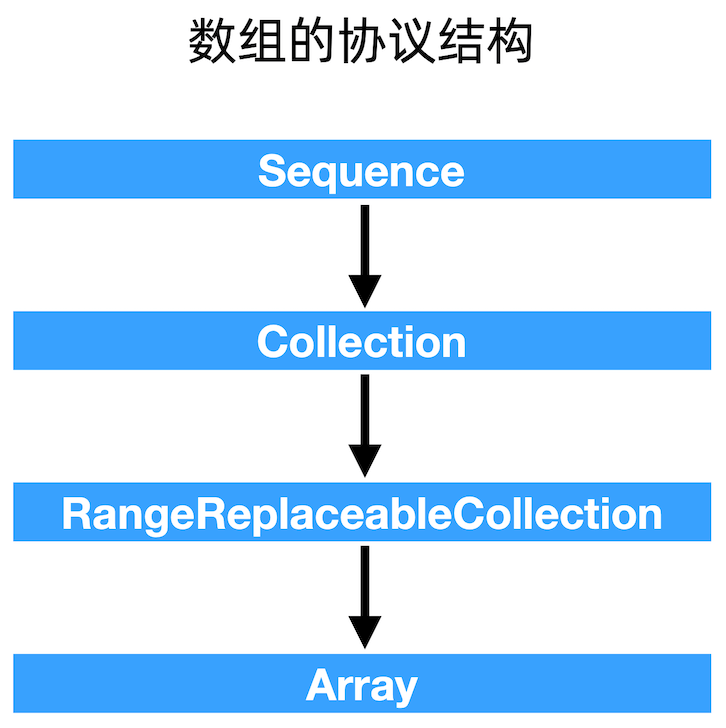
顶层设计
Sequence
一个序列(sequence)代表的是一系列具有相同类型的值,可以对这些值进行迭代。

IteratorProtocol
迭代器:Sequence 通过创建一个迭代器来提供对元素的访问。迭代器每次产生一个序列的值,并且当遍历序列时对遍历状态进行管理。
如:
|
|
next() 返回序列的下一个元素。当序列被耗尽时,next() 应该返回 nil。
定义自己的 Sequence
实现斐波那契数列:
|
|
打印结果:
|
|
IteratorProtocol 是迭代器协议,继承协议同时实现协议要求的方法,就拥有了迭代器的能力。Sequence 是序列协议,继承协议同时实现协议要求的方法,就拥有了序列的能力。
mutating 表示方法内部可以对全局变量进行修改。
Collection
一个集合(Collection)是满足下面条件的序列(Sequence):
- 稳定的 Sequence, 能够被多次遍历且保持一致;
- 除了线性遍历以外,集合中的元素也可以通过下标索引的方式被获取到;
- 和 Sequence 不同,Collection 类型不能是无限的。

Array 源码
Array 的本质是一个 Sequence。
Array 的迭代器实现基于数组的下标操作,数组的小标操作基于 buffer.getElement() 方法,buffer.getElement() 方法基于 UnsafeMutablePointer 的小标操作。
Array 的迭代器
左侧是 Array 的迭代器的底层实现。next() 方法负责返回数组的下一个元素,超出数组容量则返回空。获取数组内部元素的方式是下标访问。
右侧是 Array 的迭代器的创建。调用 IndexingItetator 传入的是 self,也就是说左面的 element 是右面传入的 Collection。

Array 的下标访问
下图是下标访问的代码实现,核心方法是 _getElement() 方法。下标方法的调用链是 subscrip(index:)→_getElement()→_buffer.getElement()。
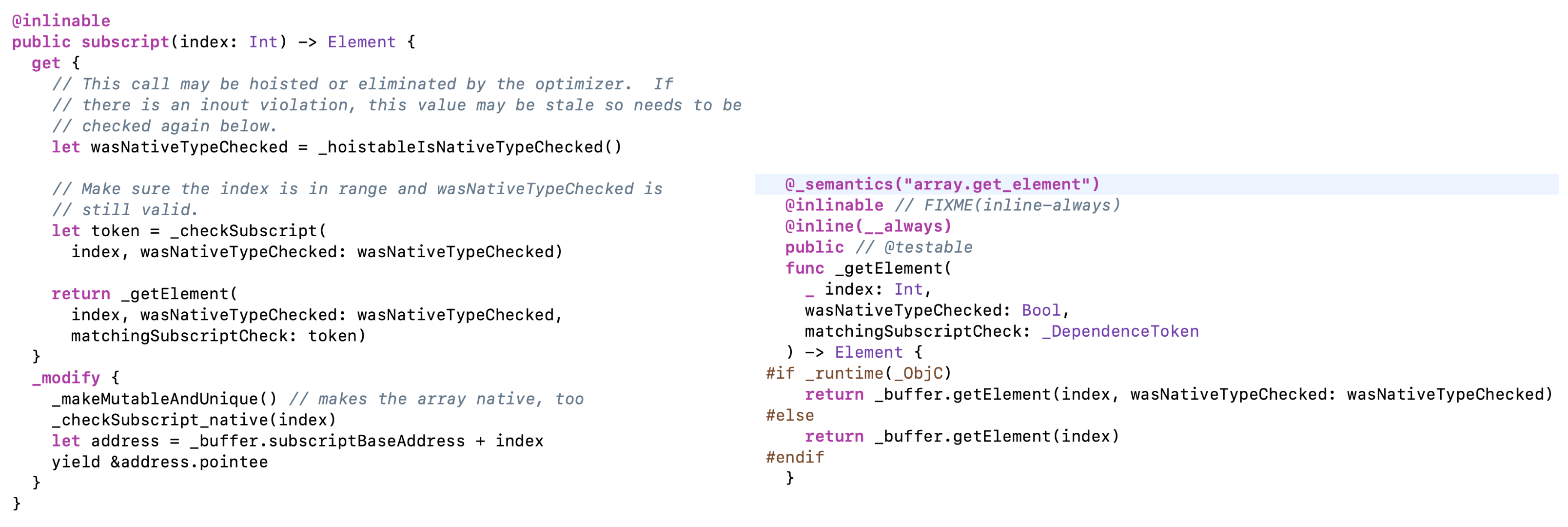
Array 的 buffer
_Buffer 的实现区分 Objc 和 Swift 两个版本,Swift 版本是 _ContiguousArrayBuffer。
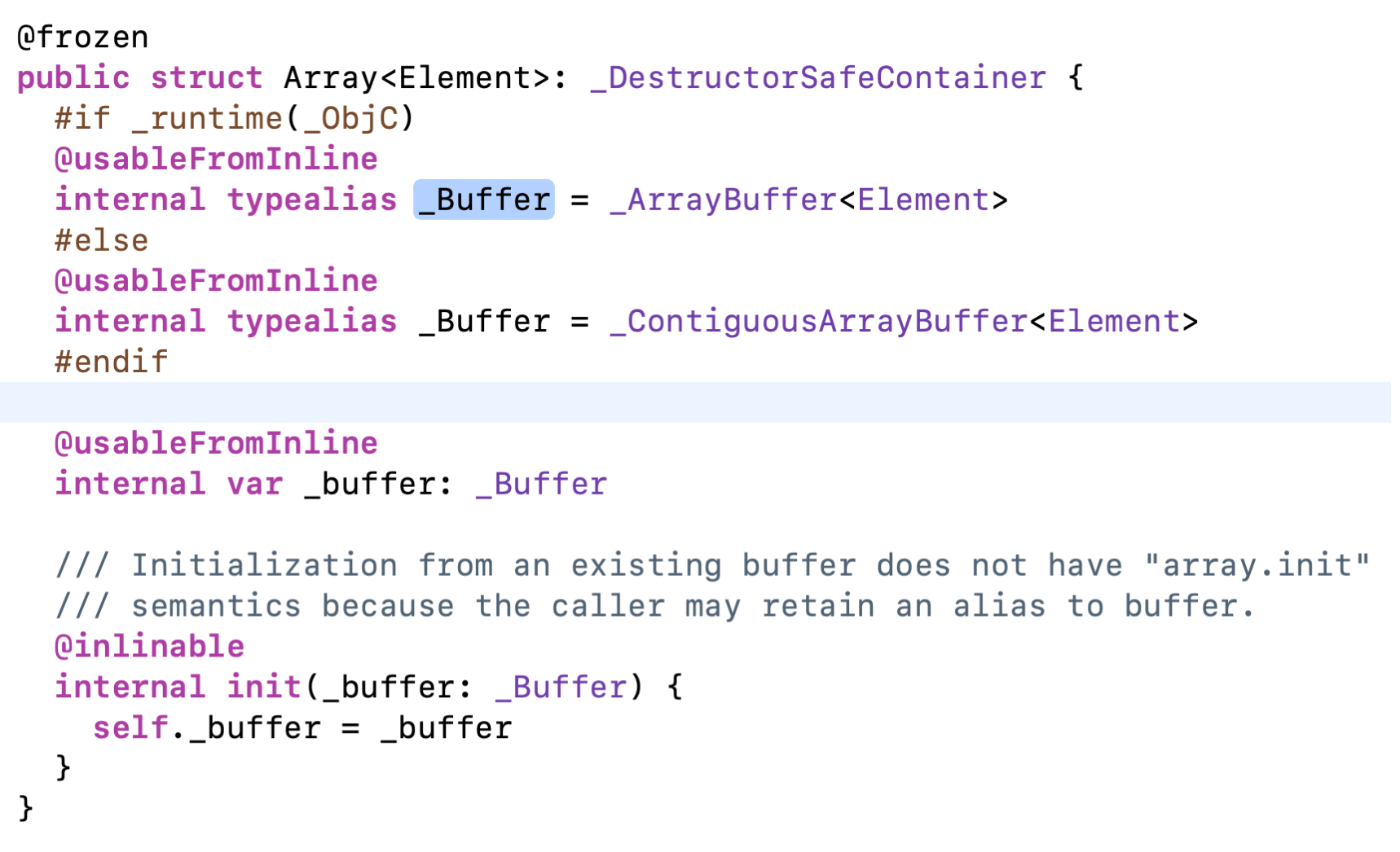
storageAddr 是通过 UnsafeMutablePointer 方法生成的一个地址,后续会对_storageAddr进行加法操作。
_ContiguousArrayBuffer

_ContiguousArrayBuffer 中 getElement() 方法的实现:
- 首先判断了是否越界;
- 通过下表访问,返回
firstElementAddress[i]中第i个元素。firstElementAddress方法中是基于 c/c++ 的指针操作。
_ContiguousArrayBuffer 的 getElement

UnsafeMutablePointer 的下标操作
UnsafeMutablePointer 是 Array 的迭代器实现中真正的指针操作实现,基于 c/c++ 实现。

至此,数组迭代器的底层代码实现已经完成。数组的 Iterator 实际上是 IndexingIterator。因为 IndexingIterator 方法传入的参数是 self,所以 next() 方法实际是对 self(数组)的下标进行操作。而数组的下标操作又会转化成 ArrayBuffer 的下标操作。
在阅读数组源码的过程中,主要包括两个步骤:
- 先看顶层设计,包括 Sequence、IteratorProtocol、Collection。
- 从关键的调用链开始,从 Iterator 的
next()方法切入。subscrip(index:)→_getElement()→_buffer.getElement()。
问题:endIndex vs count
- endIdex 是 Self.index 类型。
- count 是 Int 类型。

探索-索引
官方文档指出,所有实现 Collection 协议类,必须提供 startIndex 和 endIndex 两个属性,并且读取这两个属性的时间复杂度是 O(1) 的。因为在读取一个前向或双向的 Collection 的 count 属性时,需要遍历整个 Collection 的所有元素,所以其复杂度是 O(n) 的。
即:
对于一个随机存储的数组,获取 count 的时间复杂度是 O(1) 的。
对于一个链表实现的数组,获取 count 的时间复杂度是 O(n) 的,startIndex 和 endIndex 属性获取是 O(1) 的。在遍历一个链表数组时,如果使用 startIndex 或 endIndex 遍历,会比使用 count 遍历更加便捷。

左侧是 String 的 endIndex 和 count 的实现。endIndex 返回的是 _guits.endIndex(),是 O(1) 复杂度的。count 返回的是从 startIndex 到 endIndex 的计算结果,复杂度是非 O(1) 的。
右侧是 Array 的 endIndex 和 count 的实现。两者的实现是一样的。

探索
阅读
removeFirst方法的源码,得出removeFirst的复杂度。阅读
sort方法的源码,了解 Array 的排序方法。
实现栈和队列
Stack
栈(Stack)是一种 后入先出(Last in First Out) 的数据结构,仅限定在栈顶进行插入或者删除操作。栈结构的实现应用主要有数制转换、括号匹配、表达式求值等等。
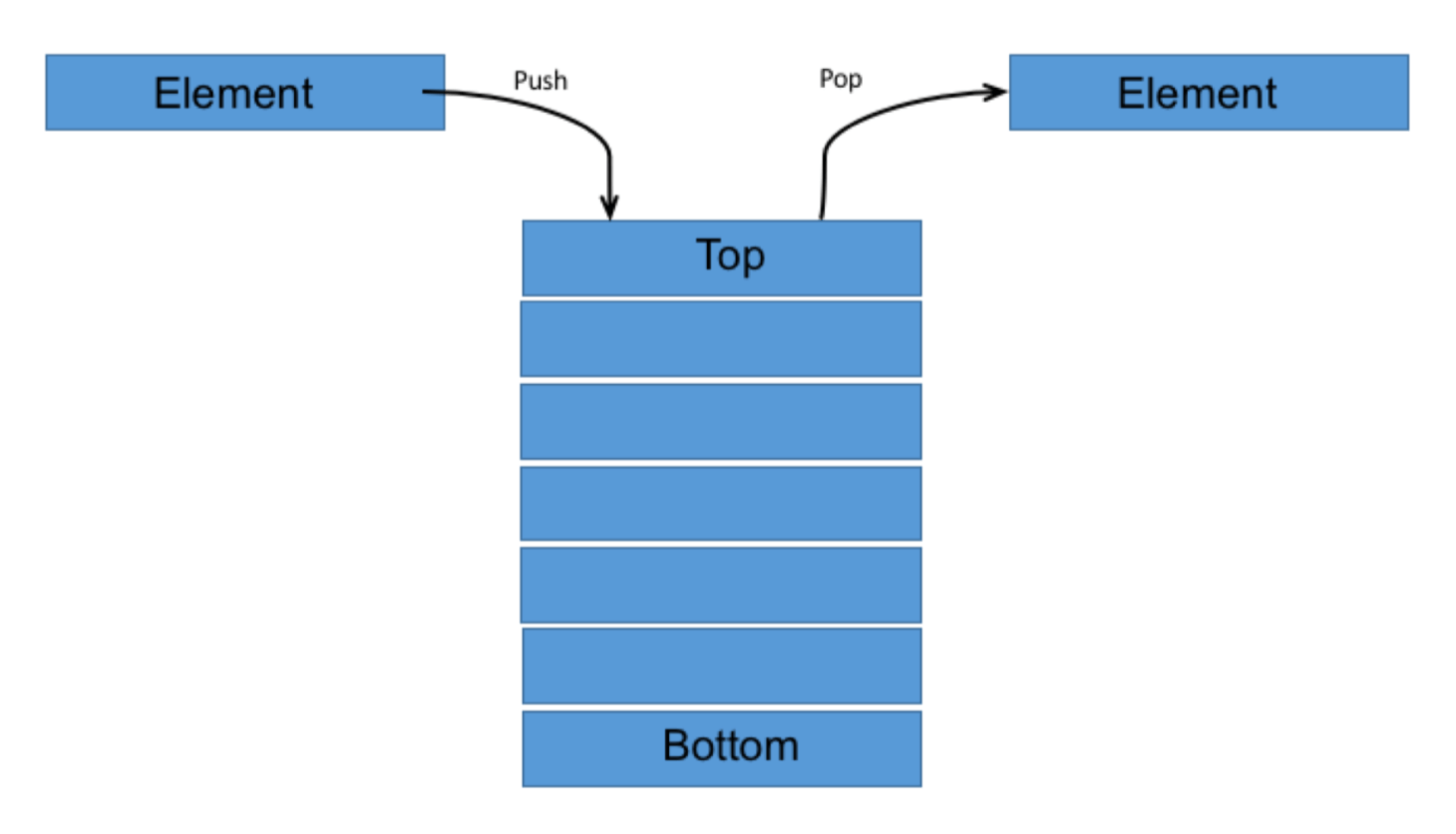
|
|
Queue
队列在生活中非常常见。排队等位吃饭、在火车站卖票、通过高速路口等,这些生活中的现象很好的描述了队列的特点:先进先出(FIFO,first in first out),排在最前面的先出来,后面来的只能排在最后面。
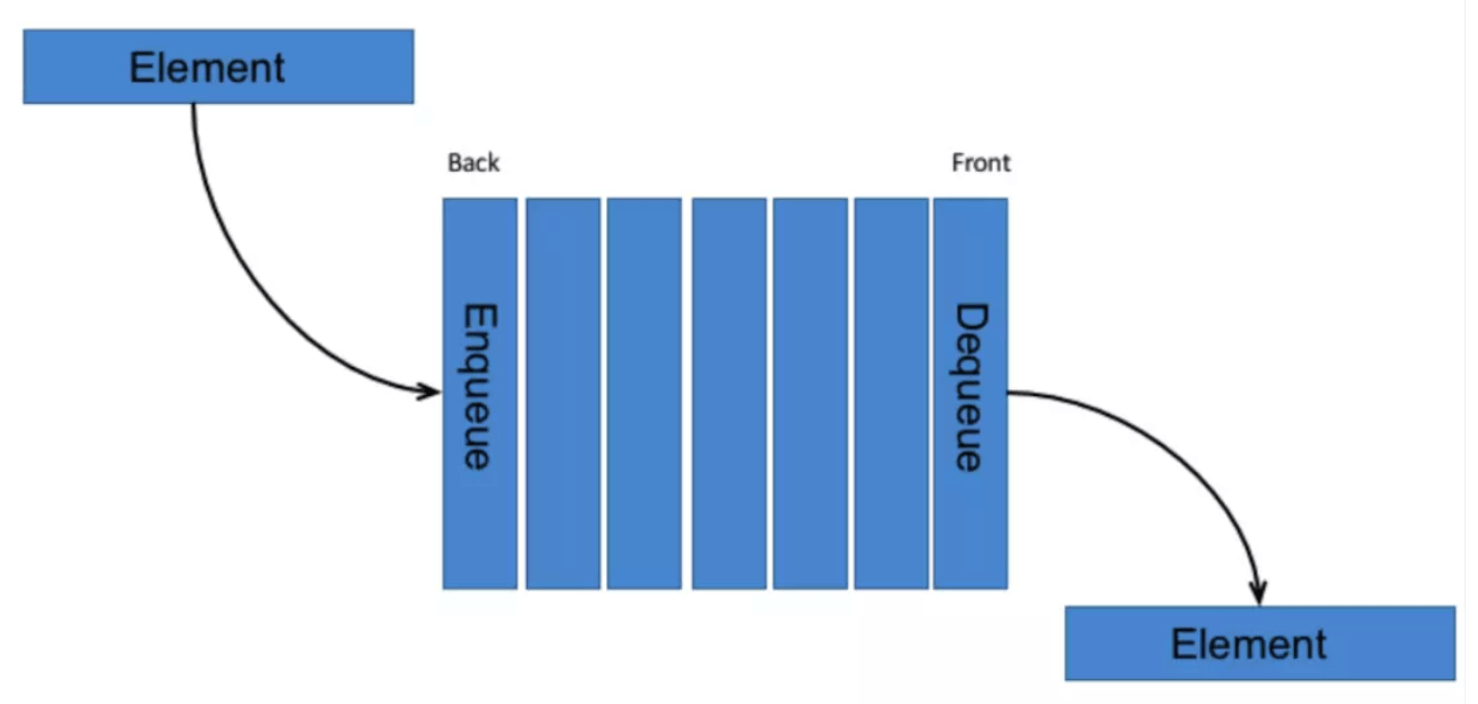
|
|
练习
尝试改造 Stack 和 Queue 的代码让实现 Sequence 协议,支持 For-in 循环。
|
|
打印结果:
|
|
总结:实现 Sequence 协议,需要实现 Sequence 创建迭代器的方法 makeIterator(),迭代器则负责实现 next() 方法序列的下一个元素,从而实现对序列的遍历。
Set
Set(集合)是指具有某种特定性质的具体的或抽象的对象汇总而成的集体。其中,构成 Set 的这些对象则称为该 Set 的元素。
集合的三个特性
- 确定性:给定一个集合,任给一个元素,该元素或者属于或者不属于该集合,二者必居其一。
- 互斥性:一个集合中,任何两个元素都认为是不相同的,即每个元素只出现一次。
- 无序性:一个集合中,每个元素的地位都是相同的,元素之间是无序的。
Swift 的集合类型写做 Set<Element>,这里的 Element 是 Set 要储存的类型。不同于数组,集合没有等价的简写。
创建 Set
1、使用初始化器语法来创建一个确定类型的空 Set:
|
|
2、使用数组字面量创建 Set:
|
|
Set 类型的哈希值
为了能让类型储存在 Set 中,它必须是可哈希的——就是说类型必须提供计算它自身哈希值的方法。
所有 Swift 的基础类型,比如 String,Int,Double 和 Bool 默认都是可哈希的,并且可以用于 Set 或者 DIctionary 的键。
报错信息:Person 没有实现 Hashable 协议。
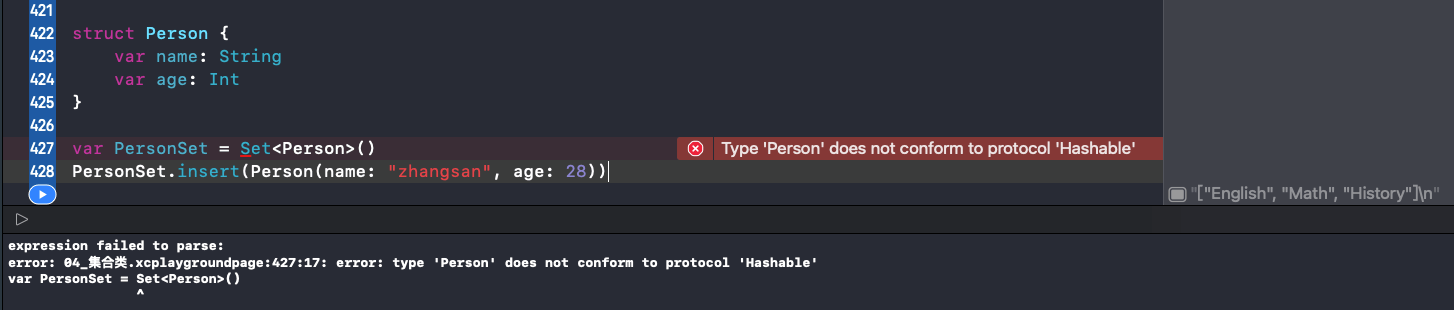
让 Person 实现 Hashable 协议:
|
|
访问和修改 Set
遍历 Set
可以使用 For-In 遍历 Set。
|
|
打印结果:
|
|
因为 Set 是无序的,如果需要顺序遍历 Set,可以使用 sorted() 方法进行排序。
|
|
打印结果:
|
|
访问 Set
使用 count 获取 Set 里元素个数。
|
|
使用 isEmpty 判断 Set 是否为空。
|
|
添加元素
insert(_:):添加一个元素到 Set。
|
|
update(with:):如果已经有相等的元素,替换为新元素。如果 Set 中没有,则插入。
|
|
在使用 update(with:) 方法时,需要保证集合内的元素实现了 Equatable 协议,用来判断两个元素是否相等。
移除元素
filter(_:):返回一个新的 Set,新 Set 的元素是原始 Set 符合条件的元素。
|
|
remove(_:):从 Set 当中移除一个元素,如果元素是 Set 的成员就移除它,并且返回移除的值。如果集合没有这个成员就返回 nil。
|
|
removeAll():移除所有元素。
|
|
removeFirst():移除 Set 的第一个元素,因为 Set 是无序的,所以第一个元素并不是放入的第一个元素。
|
|
基本 Set 操作
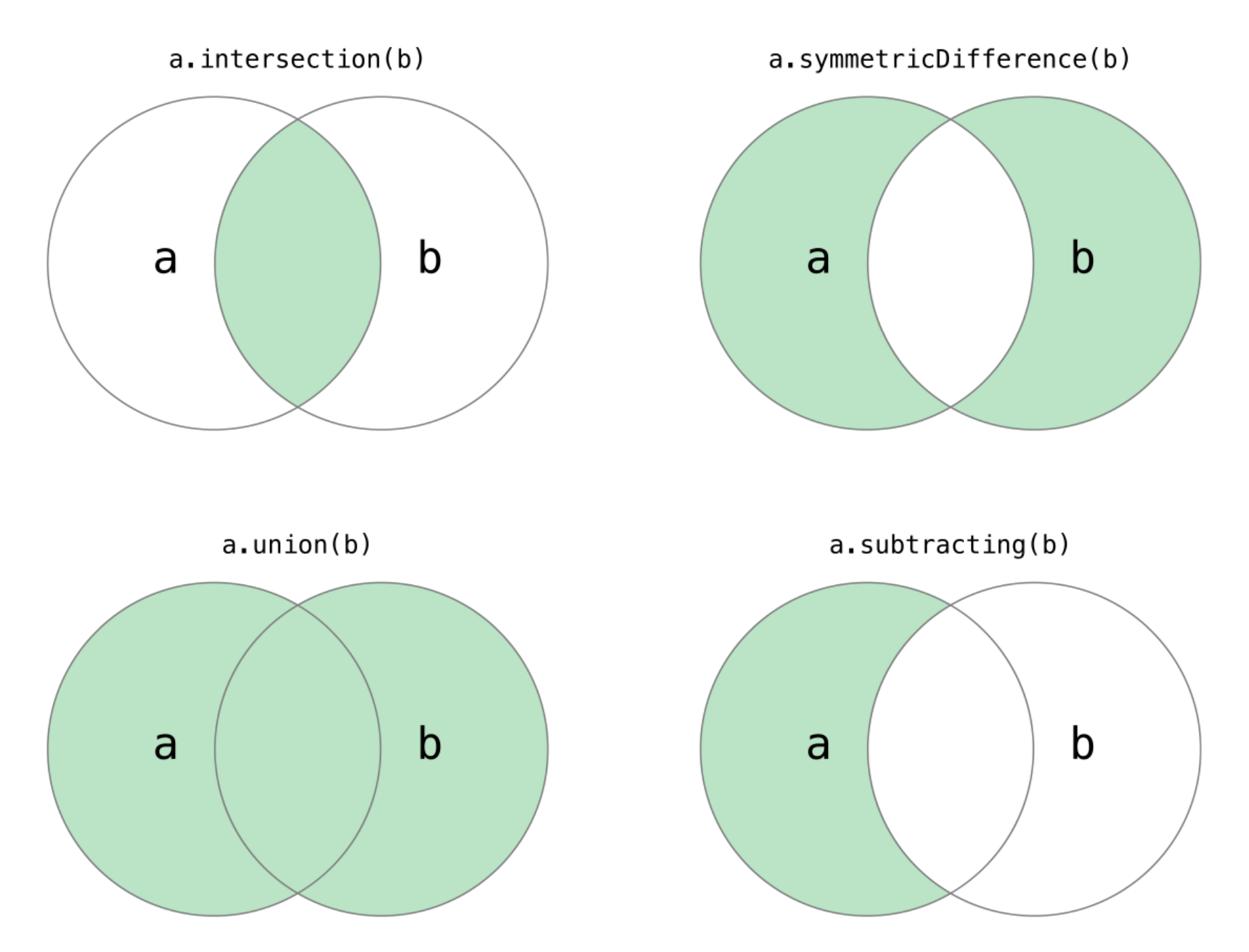
intersection(_:):交集,由属于 A 且属于 B 的相同元素组成的集合,记作 A∩B(或 B∩A)。
|
|
union(_:):并集,由属于 A 或者属于 B 的所有元素组成的集合,记作 A∪B(或 B∪A)。
|
|
symmetricDifference(_:):对称差集,集合 A 与集合 B 的对称差集定义为集合 A 与集合 B 中所有不属于 A∩B 的元素的集合。
|
|
subtracting(_:):相对补集,由属于 A 而不属于 B 的元素组成的集合,称为 B 关于 A 的相对补集,记作 A-B 或 A\B。
|
|
Set 判断方法
isSubset(of:):判断是否是另一个 Set 或者 Sequence 的子集。
|
|
isSuperset(of:):判断是否是另一个 Set 或者 Sequence 的超集。
|
|
isStrictSubset(of:) :判断是否是另一个 Set 的子集,但是又不等于另一个 Set。
|
|
isStrictSuperset(of:):判断是否是另一个 Set 的超集,但是又不等于另一个 Set。
|
|
isDisjoint(with:):判断两个 Set 是否不相交,如果不相交返回 true,如果相交返回 false。
|
|
Set-练习
- 给定一个集合,返回这个集合所有的子集。
思路1-位
解这道题的思想本质上就是元素选与不选的问题,于是就可以想到用二进制来代表选与不选的情况。“1”代表这个元素已经选择,而“0”代表这个元素没有选择。假如三个元素 A B C,那么 101 就代表 B 没有选择,所以 101 代表的子集为 AC。
|
|
打印结果:
|
|
打印结果解析:
第0个子集,二进制 000,没有元素
第1个子集,二进制 001,有一个元素 A
第2个子集,二进制 010,有一个元素 B
第3个子集,二进制 011,有两个元素 A B
第4个子集,二进制 100,有一个元素 C
第5个子集,二进制 101,有两个元素 A C
第6个子集,二进制 110,有两个元素 A B
第7个子集,二进制 111,有三个元素 A B C
使用这种方式有一个注意项,因为二进制的最大长度是64,所有 count 不能超过64位。
思路2-递归
|
|
打印结果:
|
|
index == 0,一个元素,生成两个子集,[] ["A"]
index == 1,两个元素,生成四个子集,[] ["A"] ["B"] ["A", "B"]
index == 2,三个元素,生成八个子集,[] ["A"] ["B"] ["A", "B"] ["C"] ["A", "C"] ["B", "C"] ["A", "B", "C"]
Set 实现探秘
- 先看顶层设计,再看底层源码实现。
- 从关键方法开始,沿着调用链阅读。
主要包括两个部分:
- 使用 HashTable 存放 bucket。
- 使用 elements 存放 元素。
线性探测的开放寻址法:
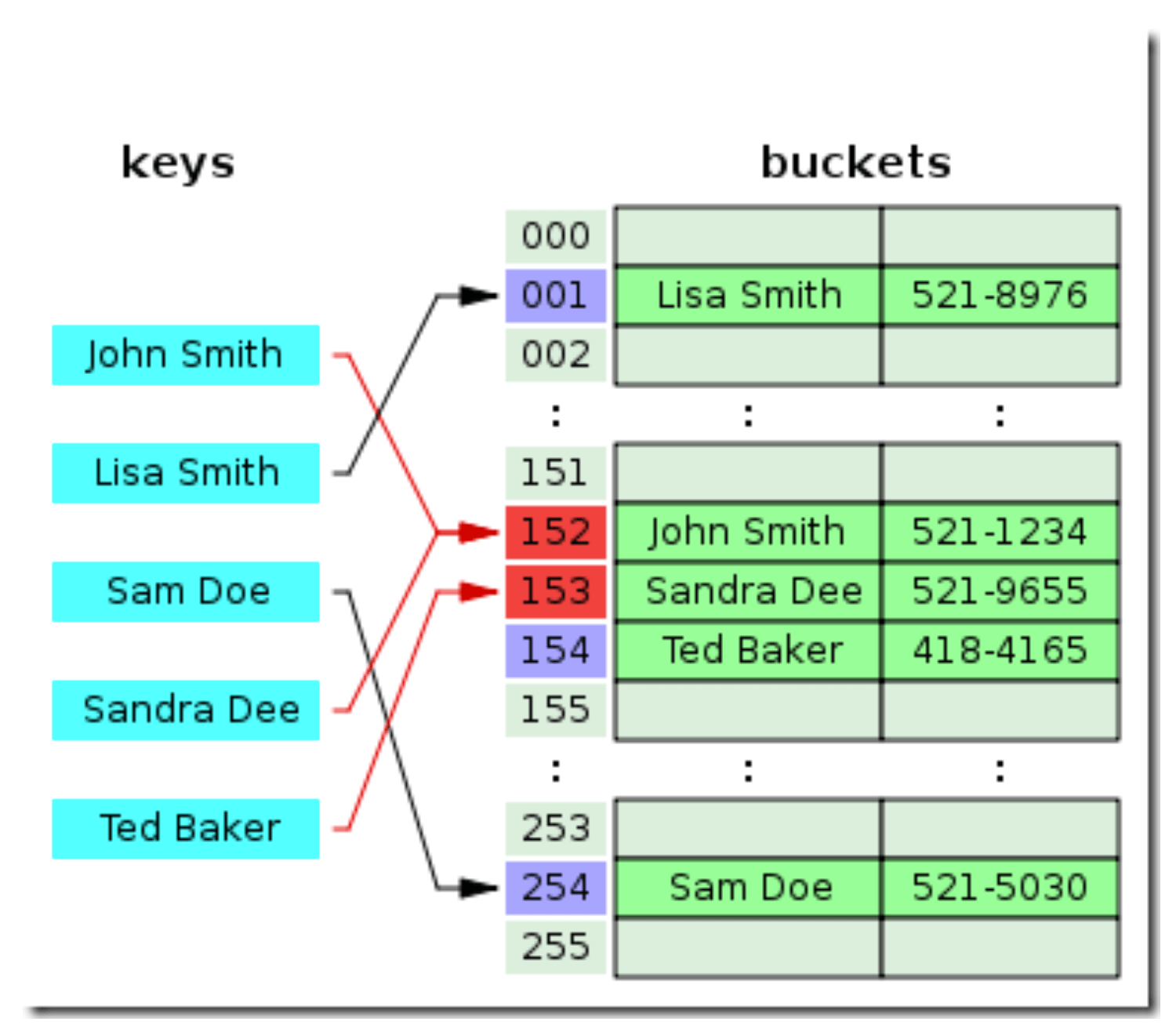
左侧是 keys,右侧是 buckets。
John Smith 通过计算找到 bucket,因为 bucket 没有被占用,所以可以直接进行存储。
Sam Doe 通过计算得找到 bucket,因为 bucket 被占用,寻找下一个 bucket01,因为 bucket01 没有被占用,所以可以使用 bucket01 进行存储。
从 Set 的 insert 说起

这是 inser() 的关键代码,用到的核心方法是 find() 和 insertNew()。
_NativeSet 的 find 方法
find():查找桶(Bucket),找到后直接使用并返回。没有找到则调用 insertNew()。主要用到了 HasTable 的 idealBucket() 和 bucket() 方法。
_isOccupied():判断桶是否被占用。

HashTable
idealBucket():找到对应的 bucket。bucket():找到当前 bucket 的后一个 bucket。

从 HashTable 的源码可以看到,bucketMask = bucketCount &-1,与上 -1 可以保证 bucket.offset & bucketMask 小于 bucketCount,hashValue & bucketMask 小于 bucketCount。

_NativeSet 的 insertNew
_isDebugAssertConfiguration() 是 debug 代码,可以直接看 else 里的代码,是调用了 HashTable 的 insertNew() 方法。
insertNew() 根据 hashValue 找到 bucket,再调用 uncheckedInitialize() 插入数据。

HashTable 的 insertNew
根据 hashValue 找到可用的 bucket。

_NativeSet 的 uncheckedInitialize
根据 _elements 首地址值加偏移量 bucket.offset 得到插入位置,插入数据。

字典
字典:储存无序的互相关联的同一类型的键和同一类型的值的集合。
字典类型的全写方式 Dictionary<Key, Value>,简写方式 [Key: Value],建议使用简写方式。其中字典的 Key 必须是可哈希的。
创建空字典
1、初始器方式
|
|
2、简写方式
|
|
3、字面量方式
|
|
字面量创建字典
字典字面量:[key1:value1, key2:value2, key3:value3]
|
|
count 和 isEmpty
count:只读属性,找出 Dictionary 拥有多少元素。
|
|
isEmpty:布尔量属性,检查字典是否为空。
|
|
遍历字典
For-In循环
|
|
打印结果:
|
|
可以通过字典的 keys 或 values 属性遍历字典的键或值的集合。
|
|
打印结果:
|
|
Swift 的 Dictionary 类型是无序的,可以通过对 keys 或 values 调用 sort() 方法排序,来遍历有序的键或值。
|
|
打印结果:
|
|
操作字典
添加或更新元素
1、使用下标添加或更新元素。
|
|
2、使用 updateValue(_:forKey) 方法添加或更新元素,返回一个字典值类型的可选项值。
|
|
字典-移除元素
1、可以使用下标脚本语法给一个键赋值 nil,实现从字典中移除该键值对。
|
|
2、也可以使用 removeValue(forKey:) 从字典中移除键值对。
|
|
在使用这个方法移除键值对时,如果键值对存在则返回其 value,如果不存在则返回 nil。
合并两个字典
merge(_:uniquingKeysWith:)
1、保留旧值
|
|
2、保留新值
|
|
firstIndex
虽然字典是无序的,但是每个kv对(键值对)在扩容之前的位置是确定的。可以通过 firstIndex 获取某个kv对的位置。
|
|
打印结果:
|
|
如果需要保持顺序的kv对,可以是用 KeyValuePairs。
|
|
字典实现探秘
从关键方法开始,沿着调用链阅读。从 set 方法开始。
从下标操作说起
字典的关键操作跟 set 方法类似,就是下标操作。
subscript(key:):字典的 set 方法,参数是 Key,返回值是可选 Value?。

lookup():get 方法通过 lookup() 方法找到对应的 value。
setValue():写入新值。
Dictionary._Variant 的 setValue
setValue(_ value: __owned Value, forKey key: Key):写入新值。需要两个参数,值、键。
源码包括 OC 和 Swift 两个实现,最后两行是 Swift 实现部分。

调用链:setValue() → asNative.setValue()。
isUniquelyReferenced():判断当前 Dictionary 是否唯一。
asNative 是 _NativeDictionary,主要负责实现 setValue() 方法👇。
_NativeDictionary 的 setValue
setValue(_ value: __owned Value, forKey key: Key, isUnique: Bool):可以看到需要三个参数,值、键、是否唯一。

实现部分和 insertNew() 类似,采用的也是开放寻址法。
如果找到了,则根据 _values 首地址值加上桶的偏移量 bucket.offset 计算出位置,存放 value。
如果没找到,则调用 _insert() 方法👇。
_NativeDictionary 的_insert
_insert(at bucket: Bucket, key: __owned Key, value: __owned Value):需要三个参数,桶、键、值。

hashTable.insert(bucket):将桶插入到哈希表里。
uncheckedInitialize():保存键值。
两个关键操作:
- 保存桶到哈希表。
- 保存键值。
_NativeDictionary 的 uncheckedInitialize
uncheckedInitialize(at bucket: Bucket, toKey key: __owned Key, value: __owned Value):需要三个参数,桶、键、值。

(_keys + bucket.offset).initialize(to: key):根据 _keys 的首地址加上桶的偏移量 bucket.offset 计算出位置,存放 key。
(_values + bucket.offset).initialize(to: value):根据 _values 的首地址加上桶的偏移量 bucket.offset 计算出位置,存放 key。
两个关键操作:
- 保存key。
- 保存value。
_NativeDictionary 的 findKey
find(_ key: Key, hashValue: Int) -> (bucket: Bucket, found: Bool):需要两个参数,键、键的哈希值。返回结果包括两个内容,桶、是否存在。

idealBucket():根据哈希值查找桶。
_isOccupied():桶是否被占用。
bucket(wrappedAfter:):从当前 bucket 开始向后查找桶。
两个关键操作:
- 根据哈希值查找对应的桶。
- 查找没有被占用的桶。