思考:
- 你理解的多线程?
- iOS的多线程方案有哪几种?你更倾向于哪一种?
- 你在项目中用过 GCD 吗?
- GCD 的队列类型
- 说一下 OperationQueue 和 GCD 的区别,以及各自的优势
- 线程安全的处理手段有哪些?
- OC你了解的锁有哪些?在你回答基础上进行二次提问;
追问一:自旋和互斥对比?
追问二:使用以上锁需要注意哪些?
追问三:用C/OC/C++,任选其一,实现自旋或互斥? 请问下面代码的打印结果是什么?
1234567891011121314151617@implementation ViewController- (void)viewDidLoad {[super viewDidLoad];dispatch_queue_t queue = dispatch_get_global_queue(0, 0);dispatch_async(queue, ^{NSLog(@"1");[self performSelector:@selector(test) withObject:nil afterDelay:.0];NSLog(@"3");});}- (void)test{NSLog(@"2");}@end请问下面代码的打印结果是什么?
12345678910111213141516@implementation ViewController- (void)test{NSLog(@"2");}- (void)touchesBegan:(NSSet<UITouch *> *)touches withEvent:(UIEvent *)event{NSThread *thread = [[NSThread alloc] initWithBlock:^{NSLog(@"1");}];[thread start];[self performSelector:@selector(test) onThread:thread withObject:nil waitUntilDone:YES];}@end
GCD
👉 GCD源码
iOS中的常见多线程方案
| 技术方案 | 简介 | 语言 | 线程生命周期 | 使用频率 |
|---|---|---|---|---|
| phread | 1.一套通用的多线程API; 2.适用于Unix\Linux\Windows等系统; 3.跨平台\可移植; 4.使用难度大; |
C | 开发者管理 | 几乎不用 |
| NSThread | 1.使用更加面向对象; 2.简单易用,可直接操作线程对象; |
OC | 开发者管理 | 偶尔使用 |
| GCD | 1.旨在替代NSThread等多线程技术; | C | 自动管理 | 经常使用 |
| NSOperation | 1.基于GCD(底层是GCD); 2.比GCD多了一些更简单使用的功能; 3.使用更加面向对象; |
OC | 自动管理 | 经常使用 |
phread 在实际开发中几乎不会用到,一般只会在加锁解锁的地方用到。另外,NSThead、GCD 和 NSOperation 底层都会用到 phread,比如创建线程等。NSThread 就是对 phread 的包装。
GCD的常用函数
GCD 中有2个用来执行任务的函数:
用同步的方式执行任务(queue:队列;block:任务)
1dispatch_sync(dispatch_queue_t queue, dispatch_block_t block);用异步的方式执行任务
1dispatch_async(dispatch_queue_t queue, dispatch_block_t block);
队列相关函数:
获取主队列
1dispatch_queue_t queue = dispatch_get_main_queue();获取全局并发队列
1dispatch_queue_t queue = dispatch_get_global_queue(0, 0);手动创建并发队列
1dispatch_queue_t queue = dispatch_queue_create("myQueue", DISPATCH_QUEUE_CONCURRENT);手动创建串行队列
1dispatch_queue_t queue = dispatch_queue_create("mySerialQueue", DISPATCH_QUEUE_SERIAL);手动创建队列组
1dispatch_group_t group = dispatch_group_create();
GCD的队列
GCD的队列可以分为2大类型
并发队列(Concurrent Dispatch Queue)
可以让多个任务并发(同时)执行(自动开启多个线程同时执行任务);
并发功能只有在异步(dispatch_async)函数下才有效;串行队列(Serial Dispatch Queue)
让任务一个接着一个地执行(一个任务执行完毕后,再执行下一个任务);
容易混淆的术语
有4个术语比较容易混淆:同步、异步、并发、串行
同步和异步主要影响:能不能开启新的线程
同步:在当前线程中执行任务,不具备开启新线程的能力;
异步:在新的线程中执行任务,具备开启新线程的能力;并发和串行主要影响:任务的执行方式
并发:多个任务并发(同时)执行;
串行:一个任务执行完毕后,再执行下一个任务;
各种队列的执行效果
| 并发队列 | 手动穿件的串行队列 | 主队列 | |
|---|---|---|---|
| 同步(sync) | 没有开启新线程 串行执行任务 |
没有开启新线程 串行执行任务 |
没有开启新线程 串行执行任务 |
| 异步(async) | 有开启新线程 并发执行任务 |
有开启新线程 串行执行任务 |
没有开启新线程 串行执行任务 |
使用sync函数往当前串行队列中添加任务,会卡住当前的串行队列(产生死锁)。
主队列是一个特殊的串行队列,async 方法在主队列中添加任务不会开启新线程,并且是串行执行任务。
并发队列 & 异步执行(async)
|
|
打印结果:
从打印结果可以看到,队列里任务的执行方式为:并发,创建新线程。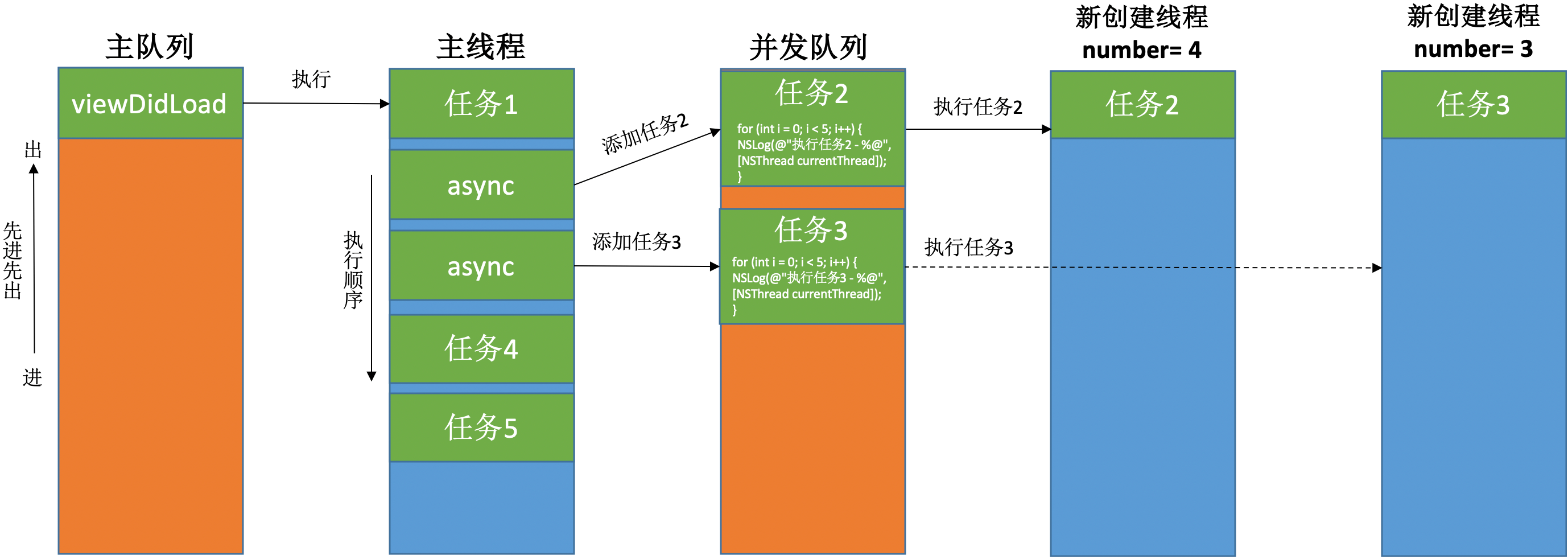
并发队列 & 同步执行(sync)
|
|
打印结果:
从打印结果可以看到,队列里任务的执行方式为:串行,主线程。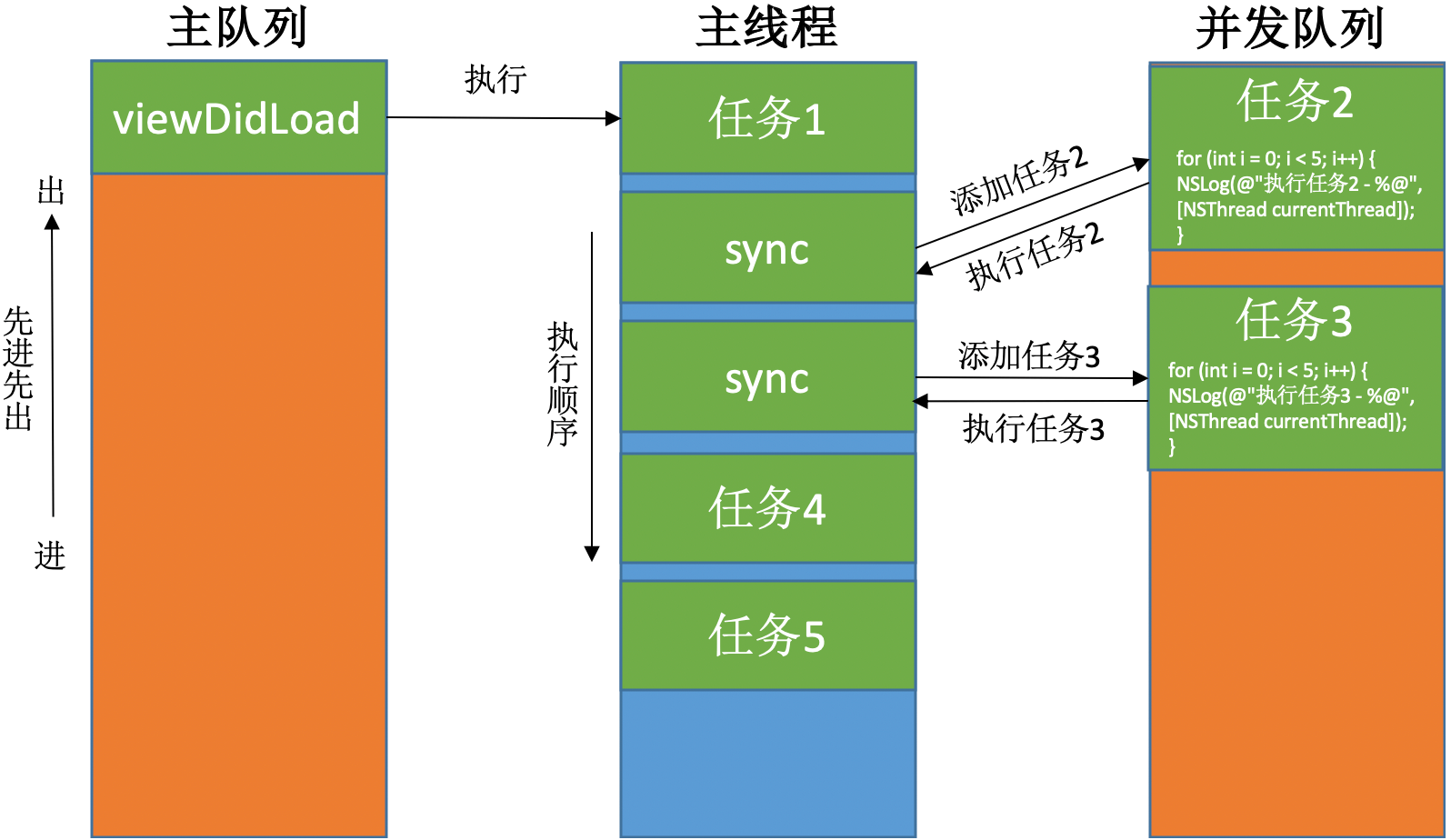
串行队列 & 异步执行(async)
|
|
打印结果:
从打印结果可以看到,队列里任务的执行方式为:串行,创建新线程。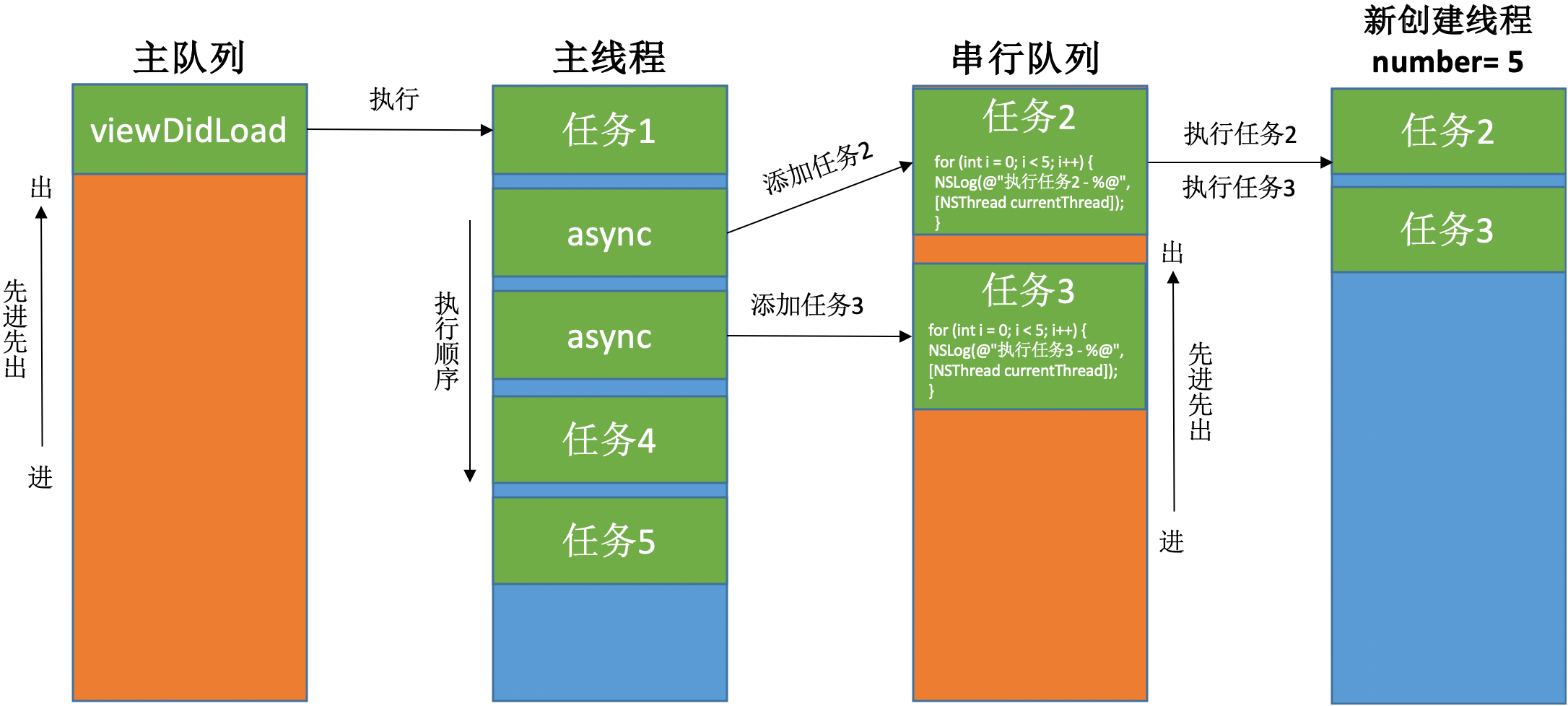
串行队列 & 同步执行(sync)
|
|
打印结果:
从打印结果可以看到,队列里任务的执行方式为:串行,主线程。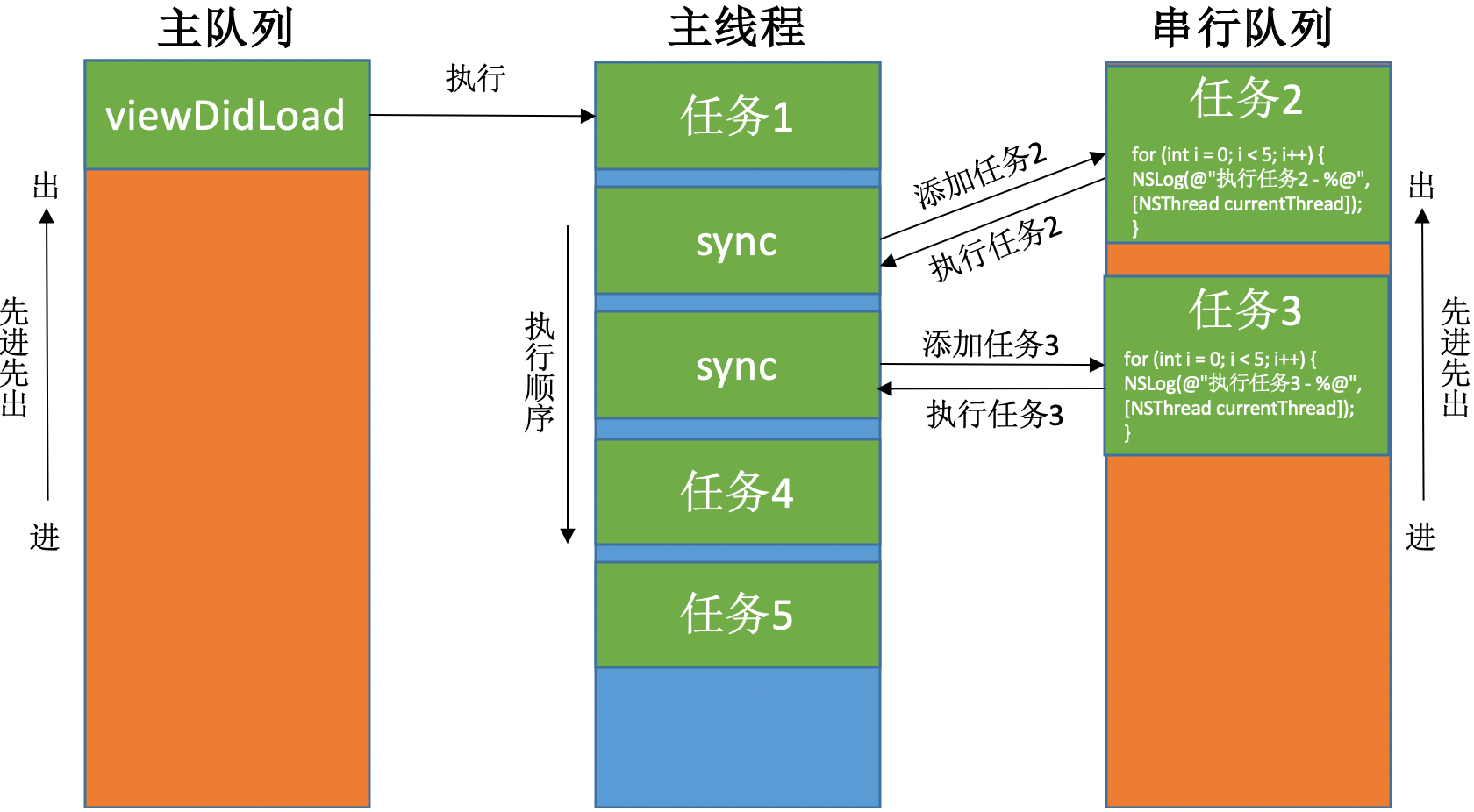
主队列 & 异步执行(async)
|
|
打印结果:
从打印结果可以看到,队列里任务的执行方式为:串行,主线程。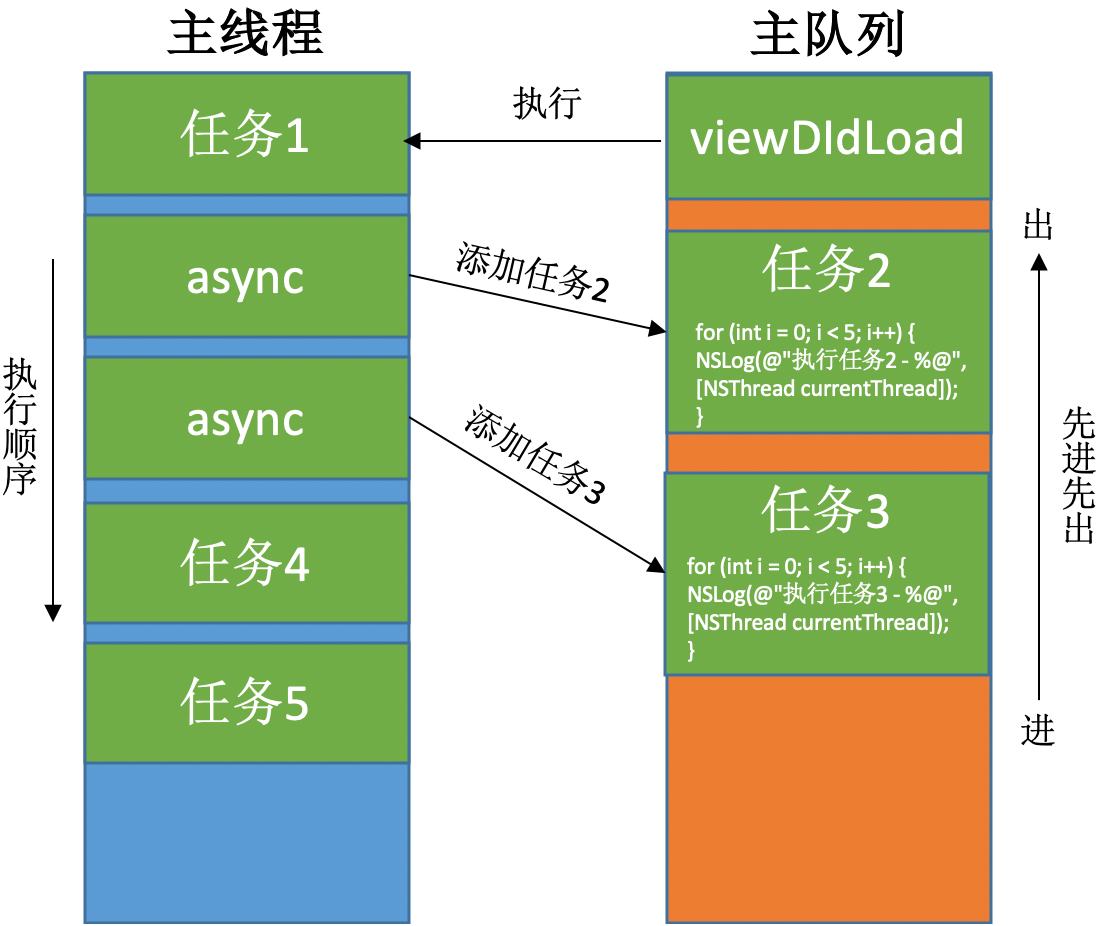
主队列 & 同步执行(sync)-> 死锁
死锁一:使用sync函数往当前串行队列中添加任务,会卡住当前的串行队列(产生死锁):
问题分析: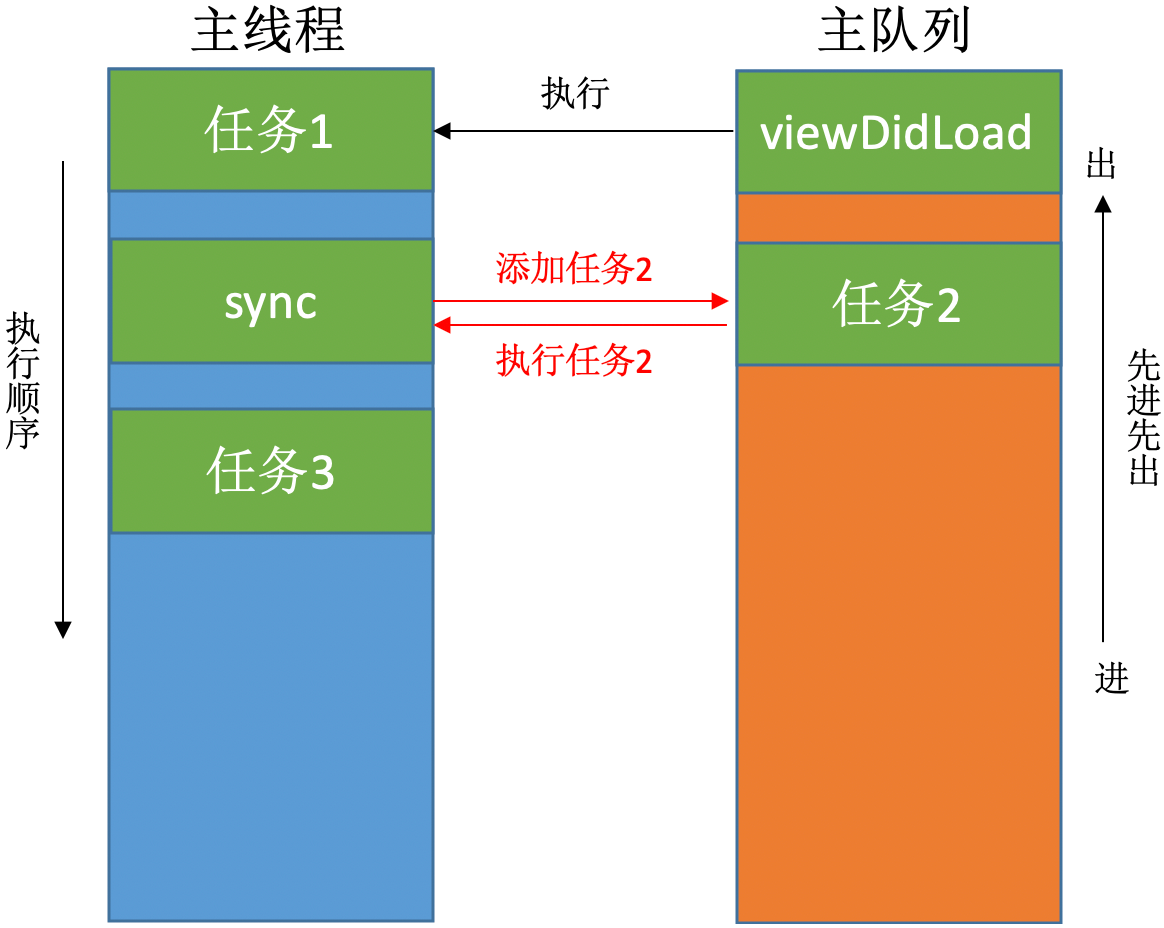
sync 函数在这里的作用有两个,第一个是添加任务2,第二个是执行任务2。因为主队列是串行队列,所以遵循先进先出原则,只有在第一个任务 viewDidLoad 执行完成后才能执行任务2。但是第一个任务 viewDidLoad 要想执行完就必须执行完 sync 函数,而 sync 函数要想执行完就必须执行完任务2,而任务2要想执行完就必须执行完 viewDidLoad … … 产生死锁。
死锁二:
问题分析: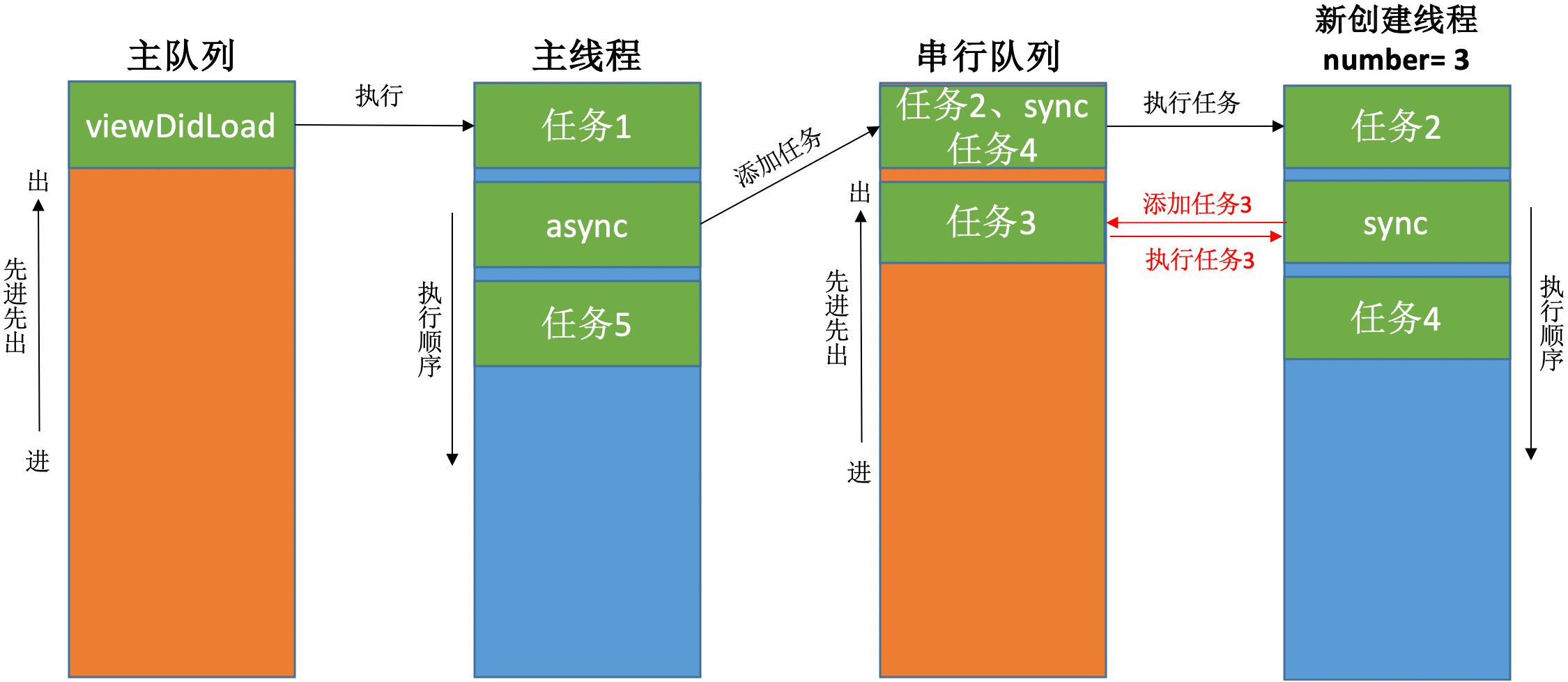
performSelector:withObject:afterDelay:
在子线程里调用 performSelector:withObject:afterDelay: 方法:
打印结果:
从打印结果可以看到,performSelector:withObject:afterDelay: 方法并没有起作用。这是因为 performSelector:withObject:afterDelay: 方法内部使用了 timer,而子线程默认没有 RunLoop,所以 performSelector:withObject:afterDelay: 方法内部的 TImer 无法调用。1和3可以打印是因为 NSLog() 方法是普通的代码,不需要 RunLoop。
解决方案 👉 手动添加 RunLoop:
打印结果:
从打印结果可以看到,performSelector:withObject:afterDelay: 方法可以正常调用了。这是因为手动为子线程添加了 RunLoop,所以 performSelector:withObject:afterDelay: 方法内部的 timer 可以正常运行了。
猜想:performSelector:withObject:afterDelay: 方法的本质是往 RunLoop 中添加定时器:
打印结果:
从打印结果可以看到,performSelector:withObject:afterDelay: 方法的调用是一个 timers 事件:RunLoop 先处理了 Sources0 事件,再处理的 Timers。
GNUstep
GNUstep 是 GNU 计划的项目之一,它将 Cocoa 的 OC 库重新开源实现了一遍。虽然 GNUstep 不是苹果官方源码,但还是具有一定的参考价值。👉 源码地址
找到 NSRunLoop.m 文件查看 performSelector:withObject:afterDelay: 方法源码:
通过源码可以得出结论:performSelector:withObject:afterDelay: 方法内部根据传入参数生成一个 GSTimedPerformer 对象(内含 NSTimer 定时器),作为 Timers 事件添加到 RunLoop 中。
performSelector:withObject:
performSelector:withObject: 方法跟 performSelector:withObject:afterDelay: 方法的实现原理不同,performSelector:withObject:afterDelay: 是定义在 RunLoop.h 文件里的 API,内部实现的本质是往 RunLoop 中添加定时器。而 performSelector:withObject: 方法的本质是调用 objc_msgSend() 方法。可以在 runtime 源码 objc4-781 里看到具体实现,找到 NSObjec.m 文件:
队列组的使用
异步并发执行任务1、任务2,在任务1、任务2都执行完毕后,再回到主线程执行任务3:
打印结果:
任务3会等到任务1和任务2都执行完成之后再执行。
GCD源码分析
dispatch_async()
在 queue.h 文件找到 dispatch_async() 方法的定义
在 queue.c 文件找到 dispatch_async() 方法的实现:
在 inline_internal.h 文件找到 _dispatch_continuation_async() 方法的实现:
在 trace.h 文件找到 _dispatch_trace_item_push 方法的实现:
dispatch_sync()
多线程的安全隐患
资源共享:1块资源可能会被多个线程共享,也就是多个线程可能会访问同一块资源,比如多个线程访问同一个对象、同一个变量、同一个文件。
当多个线程访问同一块资源时,很容易引发数据错乱和数据安全问题。
多线程安全隐患示例
卖票
|
|
打印结果:
可以看到,刚开始三个线程都卖了1张票,结果还是下14张票。在三个线程走完后总共卖了15张票,但是最后还剩3张票。无论是在卖票过程中,还是最后剩余的票数都出现了异常。

总共15张票,两个线程同时卖票,每个线程都是拿15减1,得到的手势14张票。不同的线程拿到同一个变量进行修改,就会出现问题。
存钱取钱
|
|
打印结果:
从打印结果可以看到,最后还剩350。代码中,原本有100,存了500,取了200,所以结果应该是400。
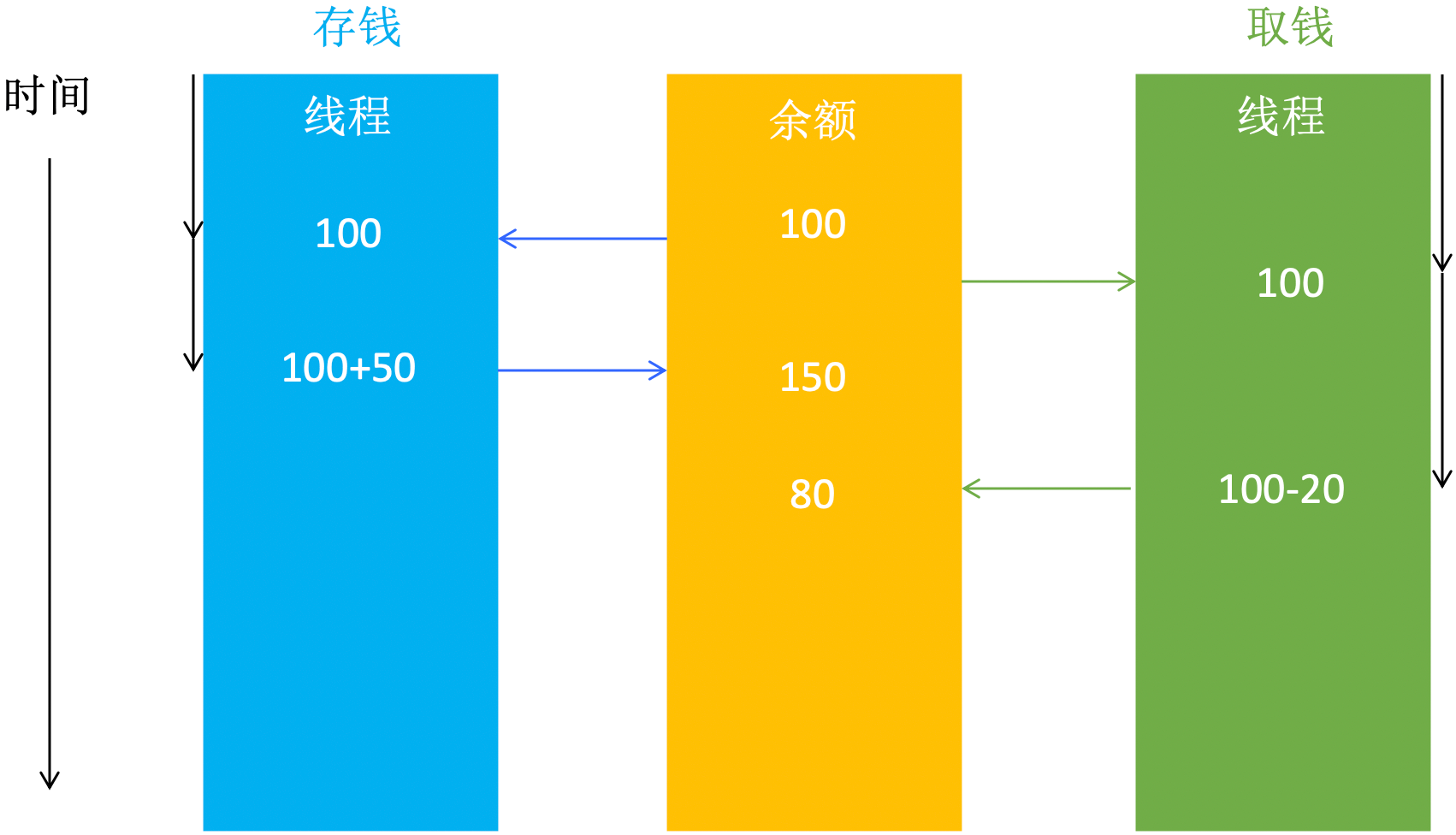
总共100元,两个线程同时拿到100元,第一个线程存了50元后余额还剩150元,第二个线程去了20元余额还剩80元。不同的线程拿到同一个变量进行修改,就会出现问题。
多线程安全隐患分析
线程A先取到变量的值17,线程B后取到变量的值17。线程A对取到的值加一(17+1=18),线程B对取到的值加一(17+1=18)。线程A将处理后的值赋值给变量(18),线程B也将处理后的值赋值给变量(18)。虽然修改了两次变量(+1),但是结果都是18: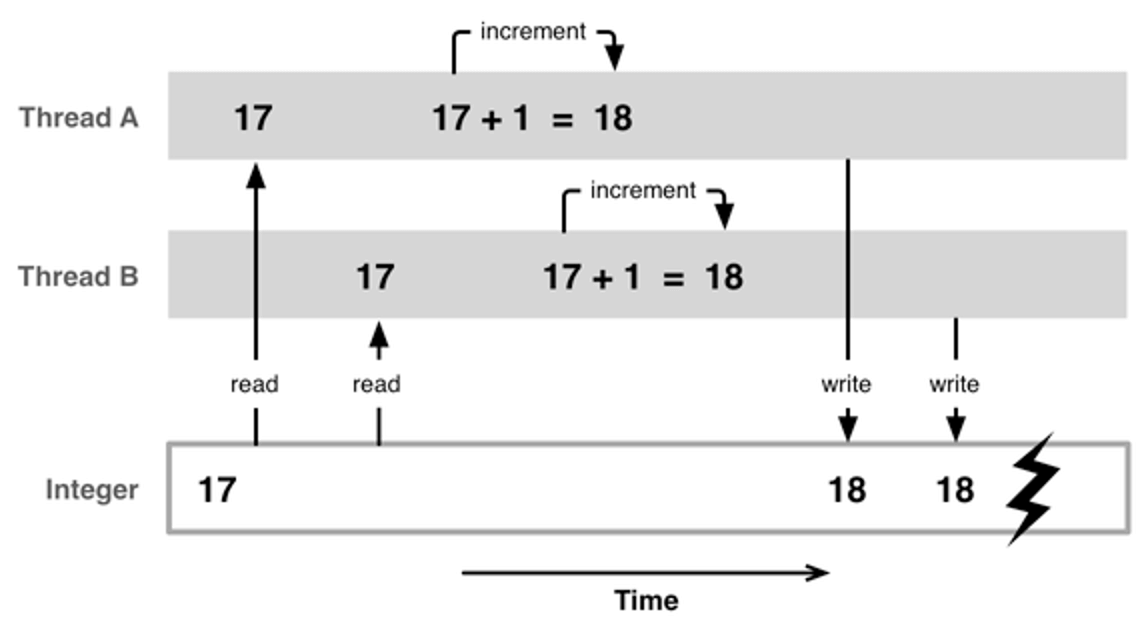
多线程安全隐患的解决方案
解决方案:使用线程同步技术(同步,就是协同步调,按预定的先后次序进行)。
常见的线程同步技术是:加锁。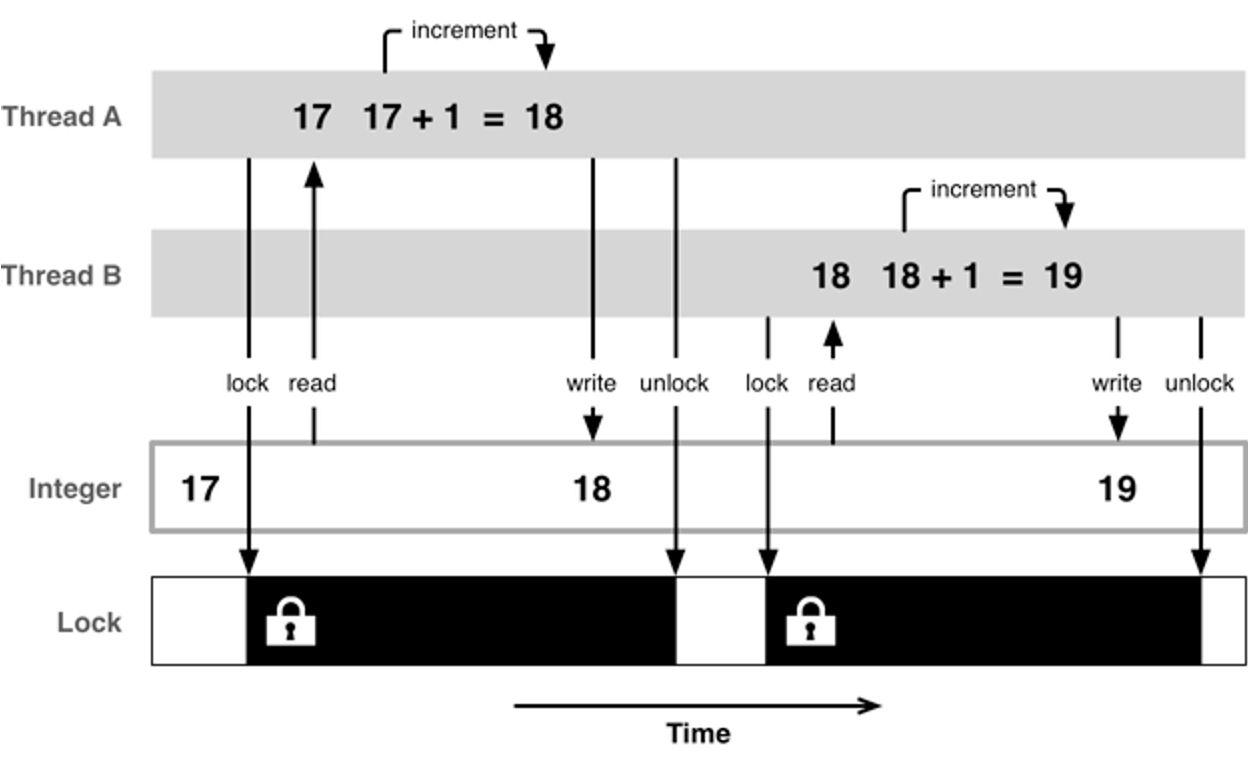
iOS中的线程同步方案
| 同步方案 | 简介 |
|---|---|
| OSSpinLock | 自旋锁 |
| os_unfair_lock | 用于取代不安全的OSSpinLock |
| pthread_mutex | 互斥锁 |
| dispatch_semaphore | 信号量 |
| dispatch_queue(DISPATCH_QUEUE_SERIAL) | 串行队列 |
| NSLock | 对mutex普通锁的封装 |
| NSRecursiveLock | 对mutex递归锁的封装,API跟NSLock基本一致 |
| NSCondition | 对mutex和cond的封装 |
| NSConditionLock | 对NSCondition的进一步封装,可以设置具体的条件值 |
| @synchronized | 对mutex递归锁的封装 |
将卖票和存钱取钱测试代码封装起来:
OSSpinLock
OSSpinLock 叫做”自旋锁”,等待锁的线程会处于忙等(busy-wait)状态,一直占用着CPU资源。目前已经不再安全,可能会出现优先级反转问题(如果等待锁的线程优先级较高,它会一直占用着CPU资源,优先级低的线程就无法释放锁)。需要导入头文件 #import <libkern/OSAtomic.h>。
忙等状态可以理解为一个 do-while 循环,不停的监测着是否解锁,这个状态下的线程会一直占用着CPU资源。正因为是处于忙等状态,所以 OSSpinLock 的效率要比其它锁都高,一旦解锁立刻就能监测到并继续执行。不再安全的原因是优先级较高的线程在等待锁时(忙等),CPU不再分配资源给其它线程,那么上锁的线程负责解锁,由于CPU没有分配资源也无法解锁,导致优先级较高的线程一直在这里等待。
- 线程调度
计算机通常只有一个CPU,在任意时刻只能执行一条机器指令,每个线程只有获得CPU的使用权才能执行指令。所谓多线程的并发运行,其实是指从宏观上看,各个线程轮流获得CPU的使用权,分别执行各自的任务。在运行池中,会有多个处于就绪状态的线程在等待CPU,JAVA虚拟机的一项任务就是负责线程的调度,线程调度是指按照特定机制为多个线程分配CPU的使用权。 - 时间片轮转调度
时间片轮转调度是一种最古老,最简单,最公平且使用最广的算法。每个进程被分配一个时间段,称作它的时间片,即该进程允许运行的时间。如果在时间片结束时进程还在运行,则CPU将被剥夺并分配给另一个进程。如果进程在时间片结束前阻塞或结束,则CPU当即进行切换。调度程序所要做的就是维护一张就绪进程列表,当进程用完它的时间片后,它被移到队列的末尾。
常用API
|
|
解决卖票和存钱取钱问题
定义 OSSpinLockDemo 继承自 LockBaseDemo。
调用 -(void)moneyTest 打印结果:
调用 -(void)ticketTest 打印结果:
因为要修改的有两个变量,一个是存钱取钱里的余额,一个是卖票里的剩余票数,所以要有两把锁分别对应这两个变量。一旦有线程对 OSSpinLock 上锁后,其它线程再遇到 OSSpinLock 时会阻塞住,等待 OSSpinLock 解锁在继续向下执行。
上面👆的例子是将 OSSpinLock 锁对象放到了实例对象里,也可以将 OSSpinLock 锁对象放到类对象里:
类方法 + (void)initialize 只会被系统调用一次,但是允许被开发者调用,所以使用 dispatch_once 保证类对象的 moneyLock_ 锁只初始化一次。
或者:
使用 static 关键字,将 ticketLock 锁保存在全局区,保证只初始化一次。
OSSpinLock 汇编分析
相关汇编代码:
jne:j 是 jump,ne 是条件。
callq:函数调用。
syscall:系统调用。lldb 指令:
setp:执行一行OC代码。
stepi:stepinstruction 的简写,执行一行汇编代码,也可以简写为 si。(如果敲的过快可能会出现异常)
next:执行一行OC代码。
nexti:执行一行汇编代码。
stepi 和 nexti 的区别:在遇到函数调用是,stepi 会进入调用的函数,nexti 不会进入。
c:continue 的简写,继续执行。
(重复敲回车会执行上一个 lldb 指令)
查看汇编代码方法
👉 修改 LockBaseDemo 类里的 - (void)__saleTicket 方法,设置睡眠时间为 60s,这样可以有足够的时间查看第二次加锁时的汇编代码。修改 - (void)ticketTest 方法,创建十条线程调用 - (void)__saleTicket 方法:
第一次加锁后,在第二次尝试加锁时,就可以有足够多的时间查看其汇编代码,在断点处查看 Debug -> Debug Workflow -> Always Show Disassembly。
查看 OSSpinLock 汇编代码
可以看到第一次调用 - (void)__saleTicket 方法是在 Thread 9 并加锁。第二次调用 - (void)__saleTicket 方法是在 Thread 10,因为此时的自旋锁处于上锁状态,所以 Thread 10 处于等待锁的状态。重复执行 si 指令,到第11行时会调用 OSSpinLocklock 函数: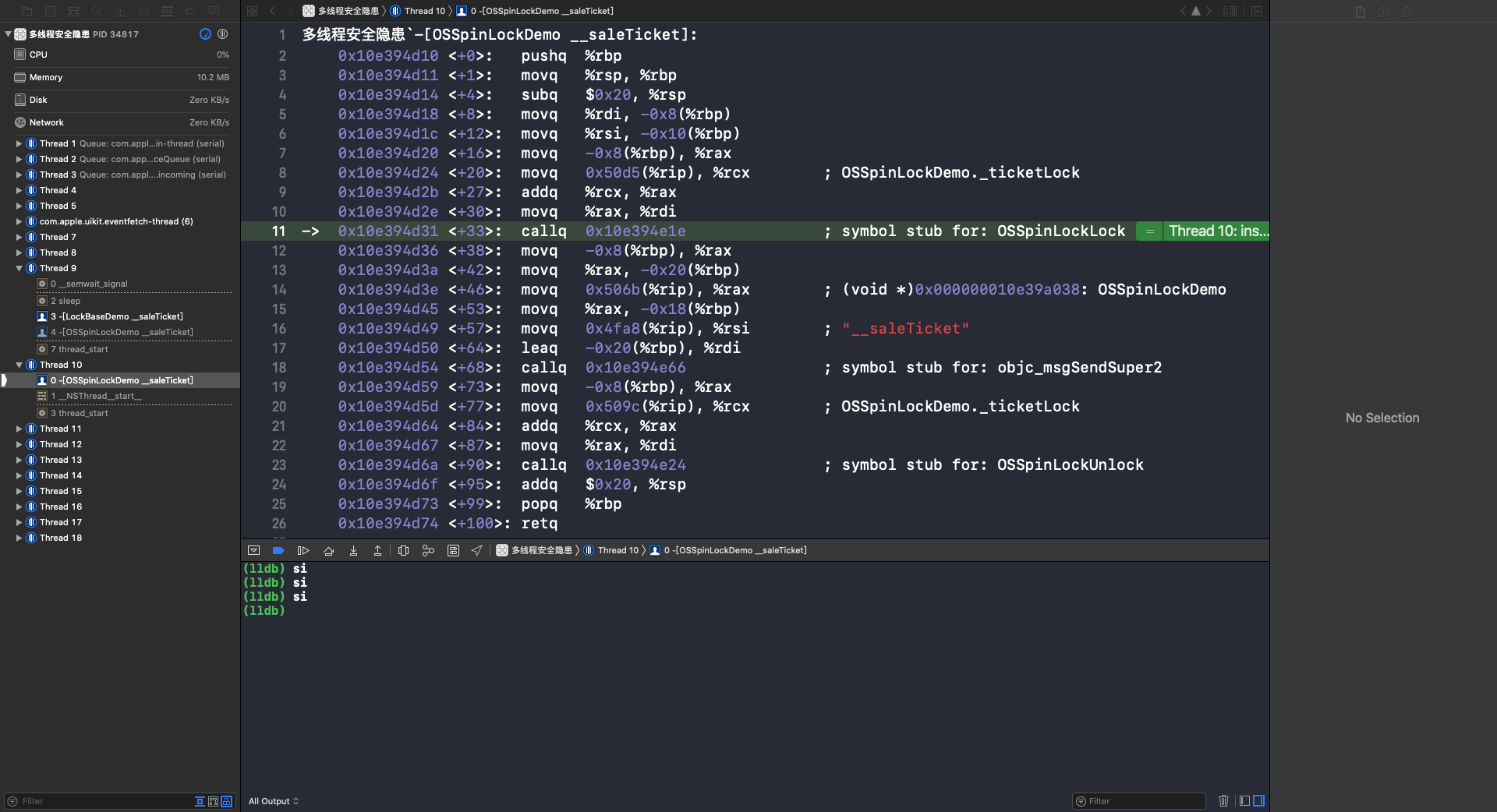
使用 si 指令进入到调用函数: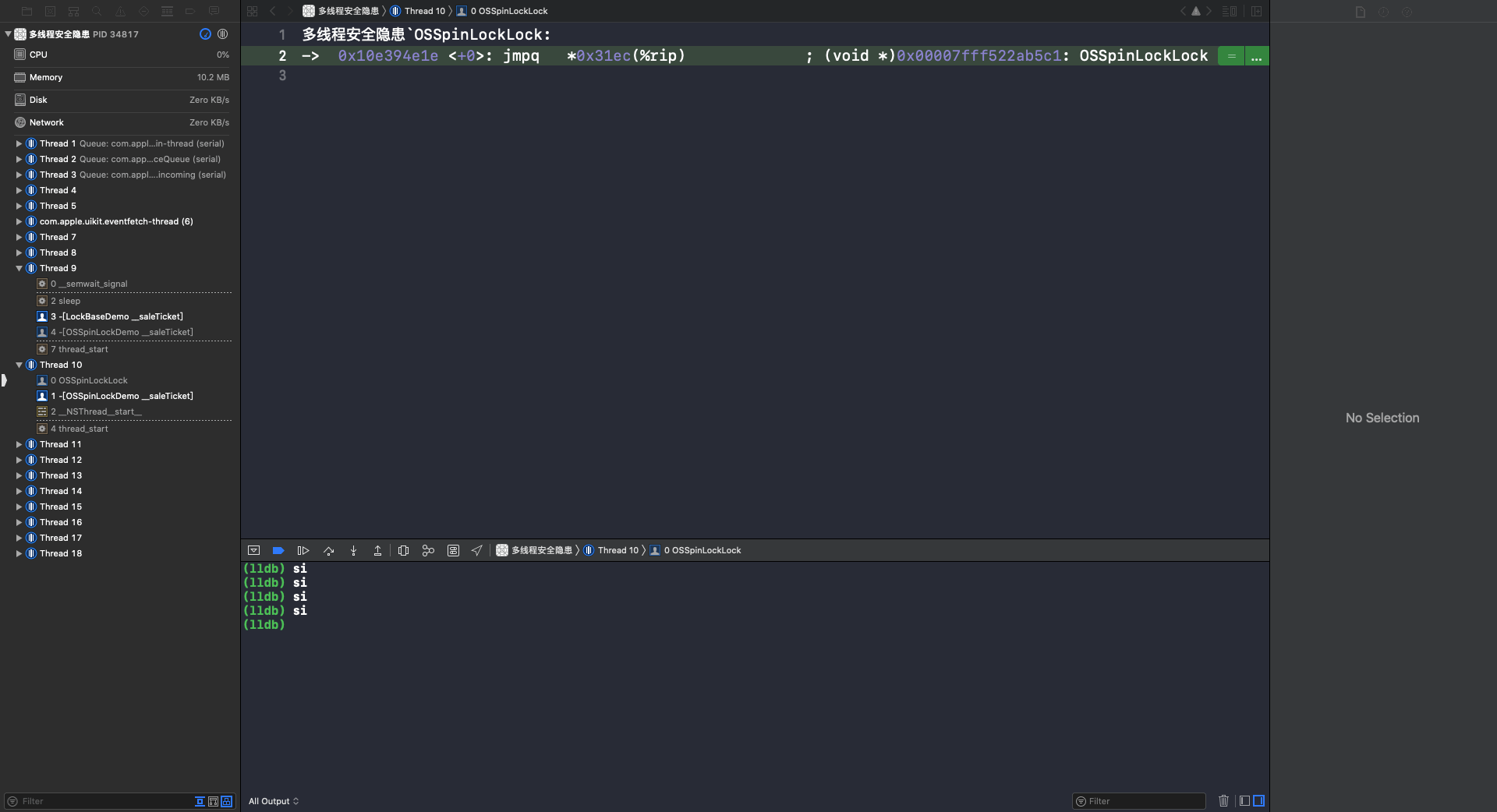
重复执行 si 指令,在第6行通过 jne 跳转到 _OSSpinLockLockSlow 函数: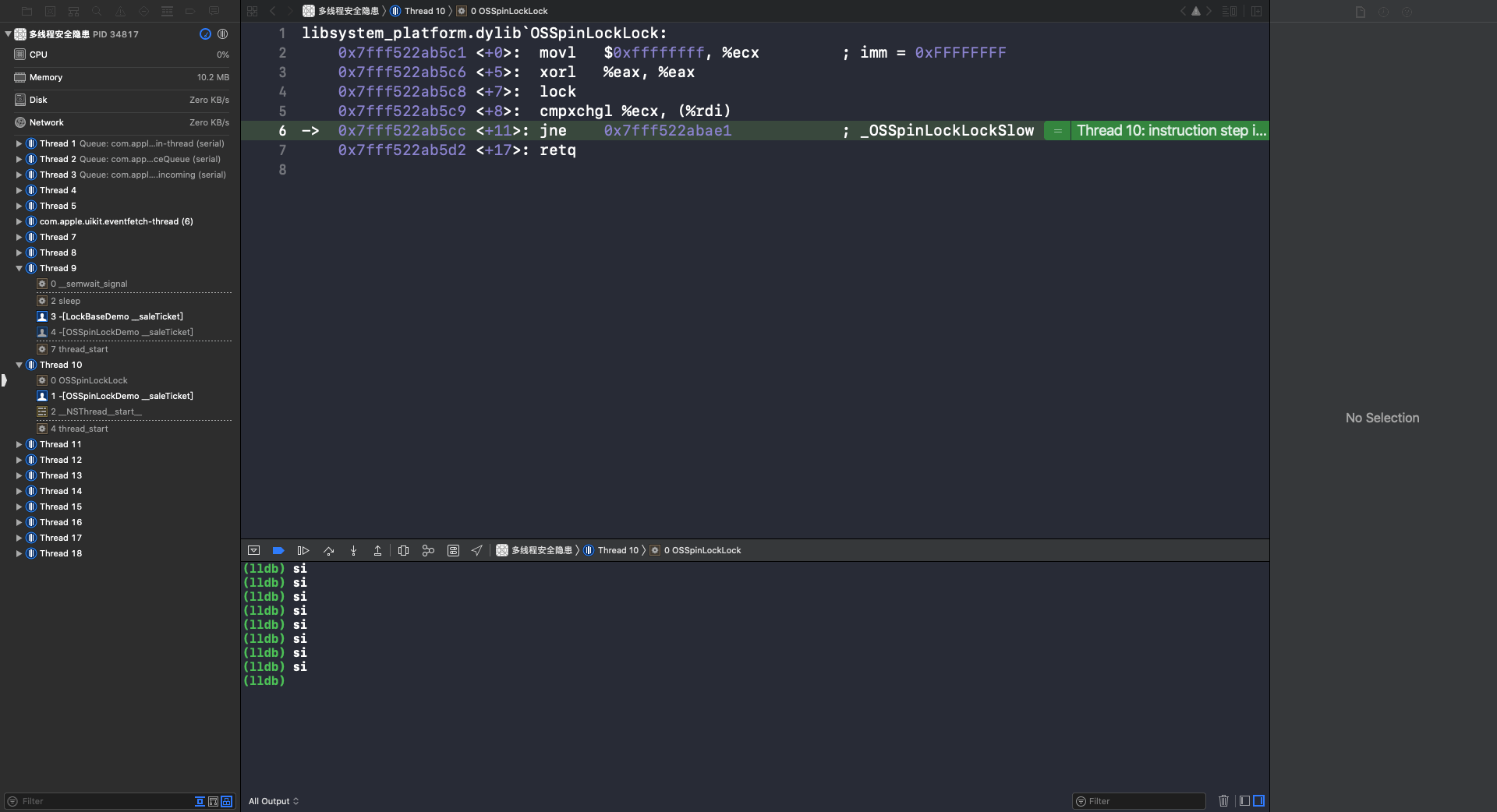
_OSSpinLockLockSlow 函数是自旋锁的核心代码,从第6行到第19行是一个 while 循环(🔎自旋锁标志)。因为 Thread 9 已经加过锁并且还没有解锁,所以这里会一直循环执行,等待 Thread 9 解锁。可以看到第14行和第16行是跳出 while 循环的判断: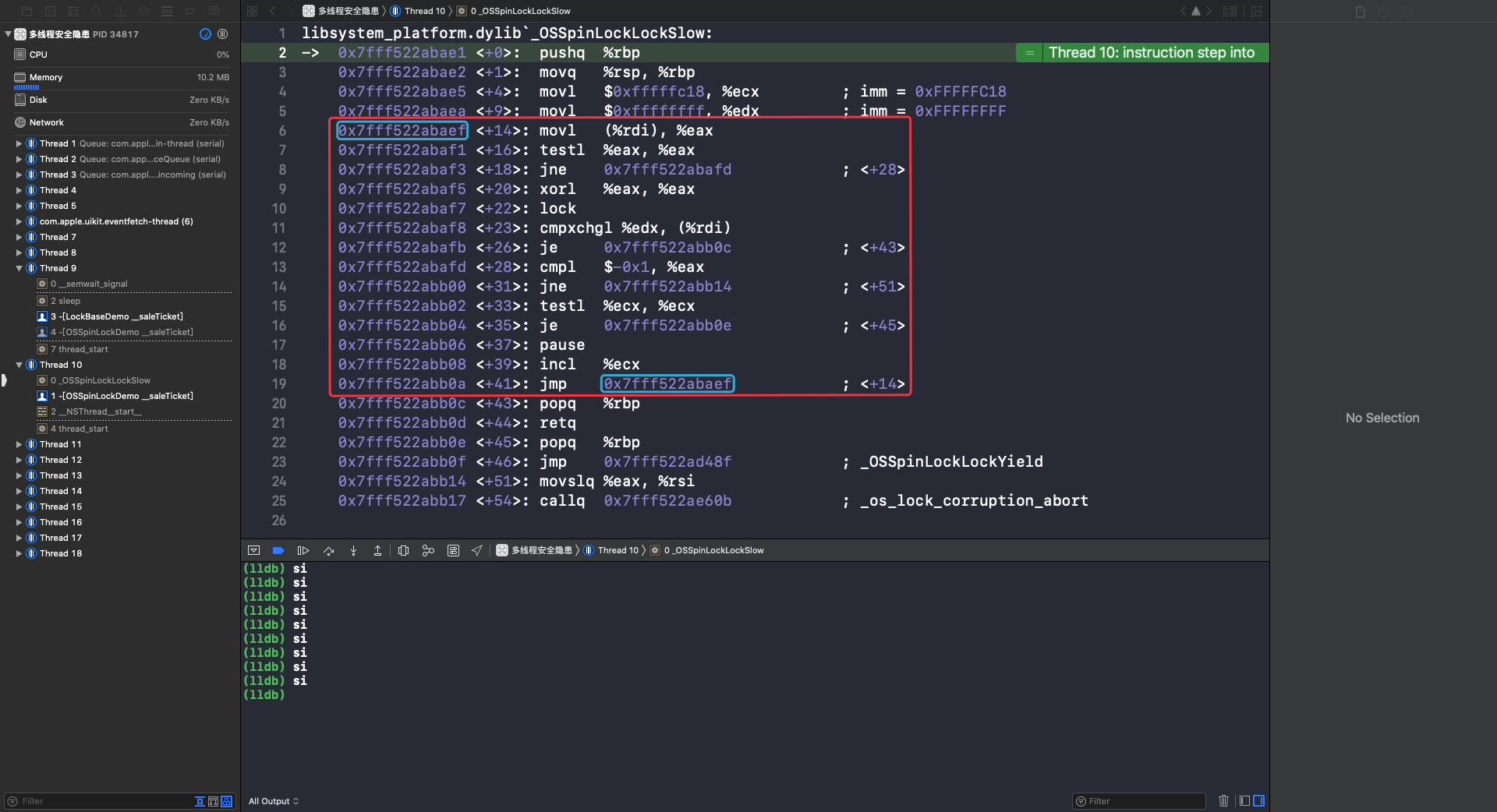
os_unfair_lock
OSSpinLock 在以前是性能最高的一种锁,但是由于不再安全(优先级反转问题),苹果已经不建议使用了,从 iOS10 开始推出了替代它的 os_unfair_lock。需要导入头文件 #import <os/lock.h>。
常用API
|
|
解决卖票和存钱取钱问题
定义 OSUnfairLockDemo 继承自 LockBaseDemo。
打印结果同 OSSpinLock。
- 死锁
如果加锁后没有解锁,其它线程就会进入等待,永远无法往下继续执行。这种由于没有解锁造成的其它线程的等待叫做死锁。
os_unfair_lock 汇编分析
根据“查看汇编代码方法”查看 os_unfair_lock 第二次尝试加锁的汇编代码。
可以看到第一次调用 - (void)__saleTicket 方法是在 Thread 8 并加锁。第二次调用 - (void)__saleTicket 方法是在 Thread 15,因为此时的自旋锁处于上锁状态,所以 Thread 15 处于等待锁的状态。重复执行 si 指令,到第11行时会调用 os_unfair_lock_lock 函数: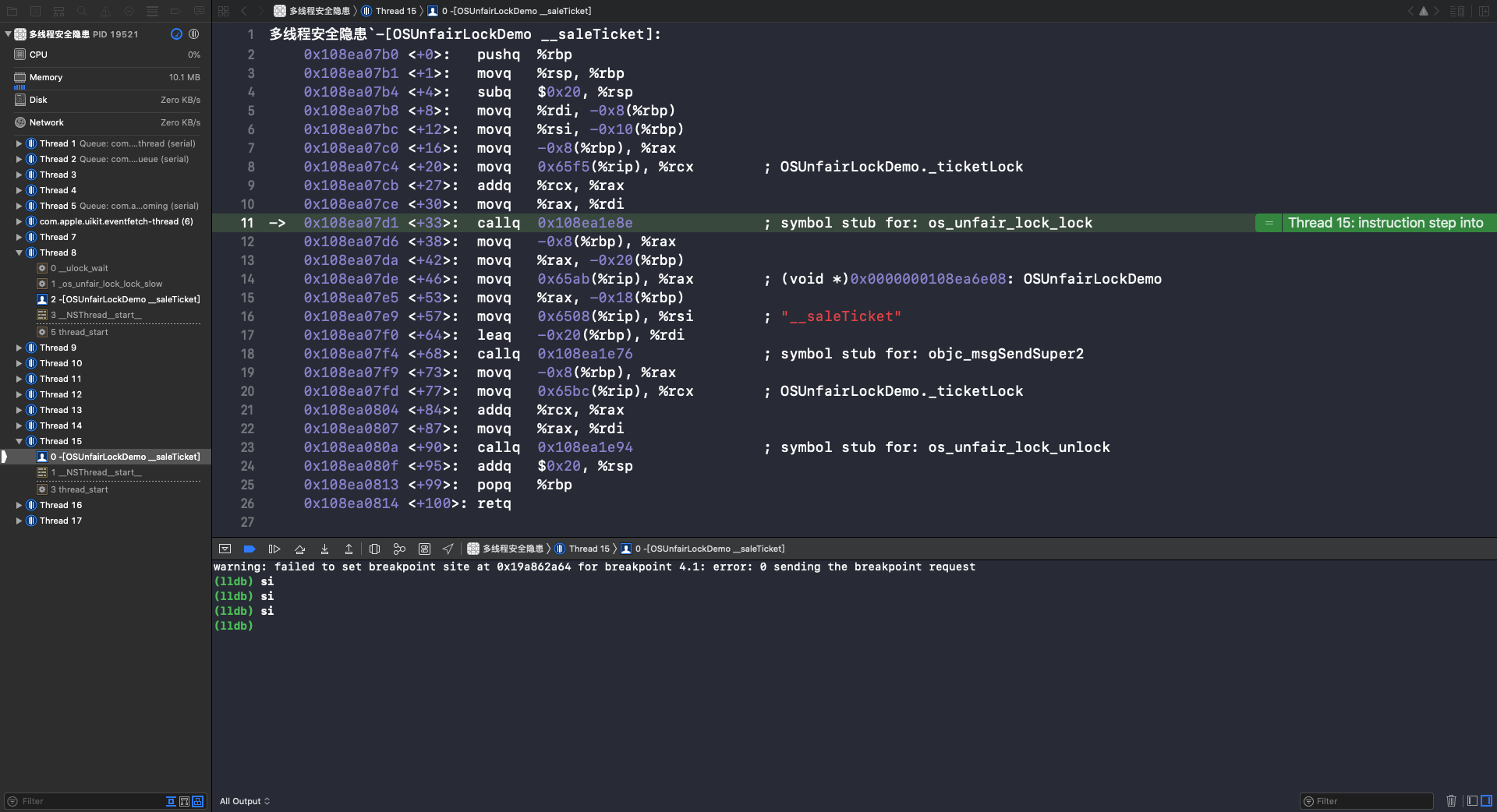
使用 si 指令进入到 os_unfair_lock_lock 函数: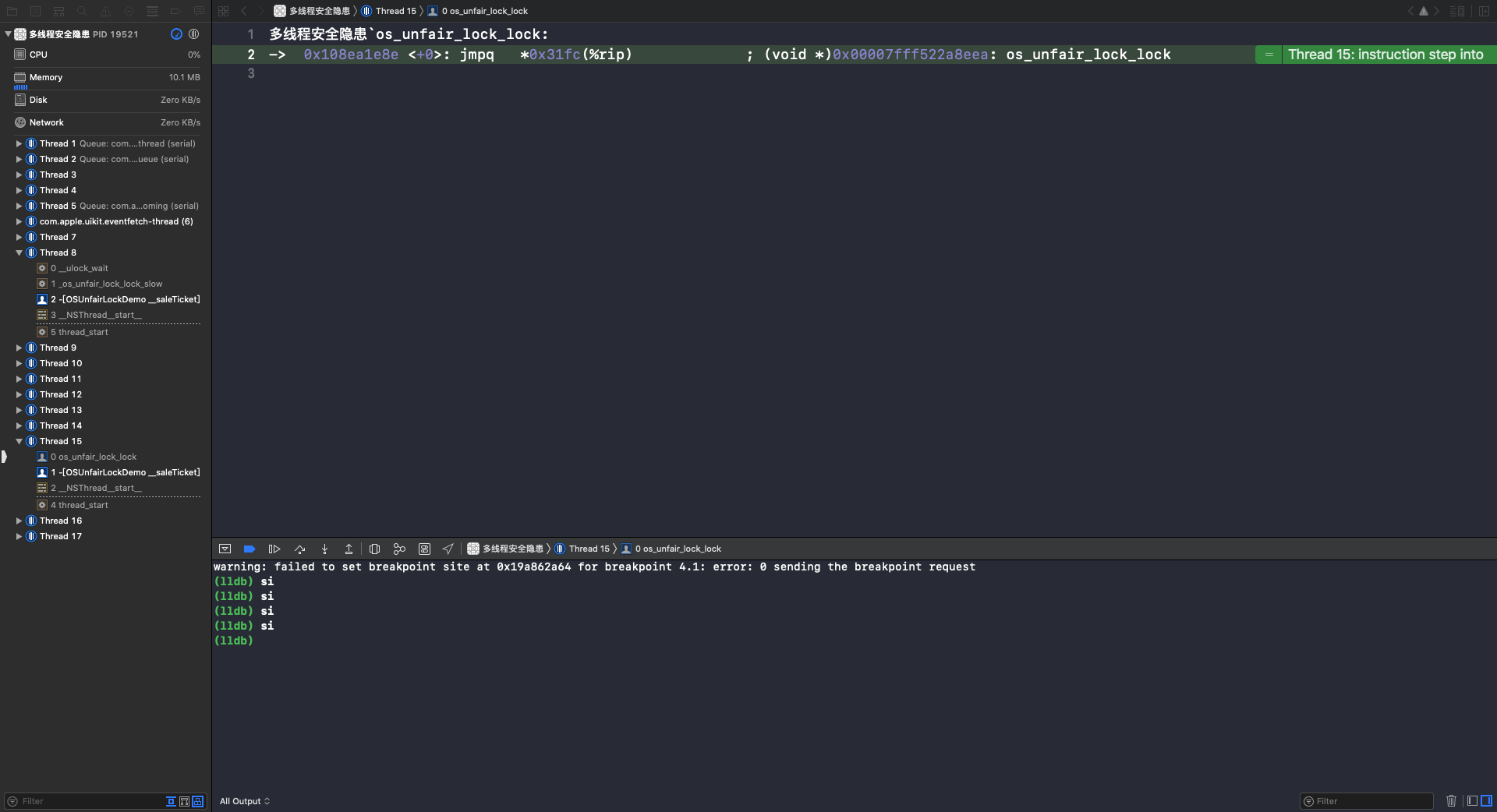
重复使用 si 指令,进入 _os_unfair_lock_lock_slow 函数: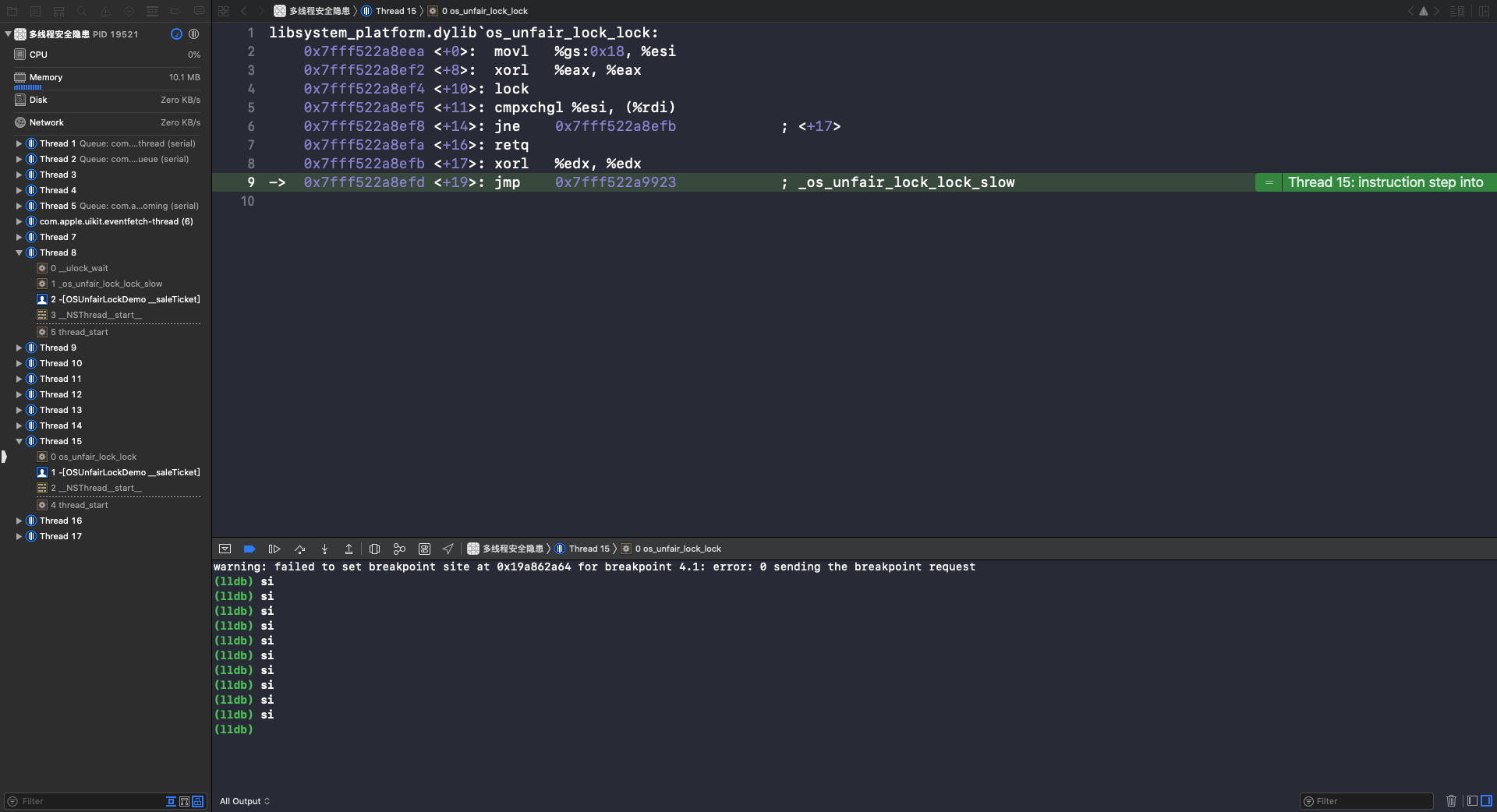
使用 si 指令,第56行会调用 __ulock_wait 函数: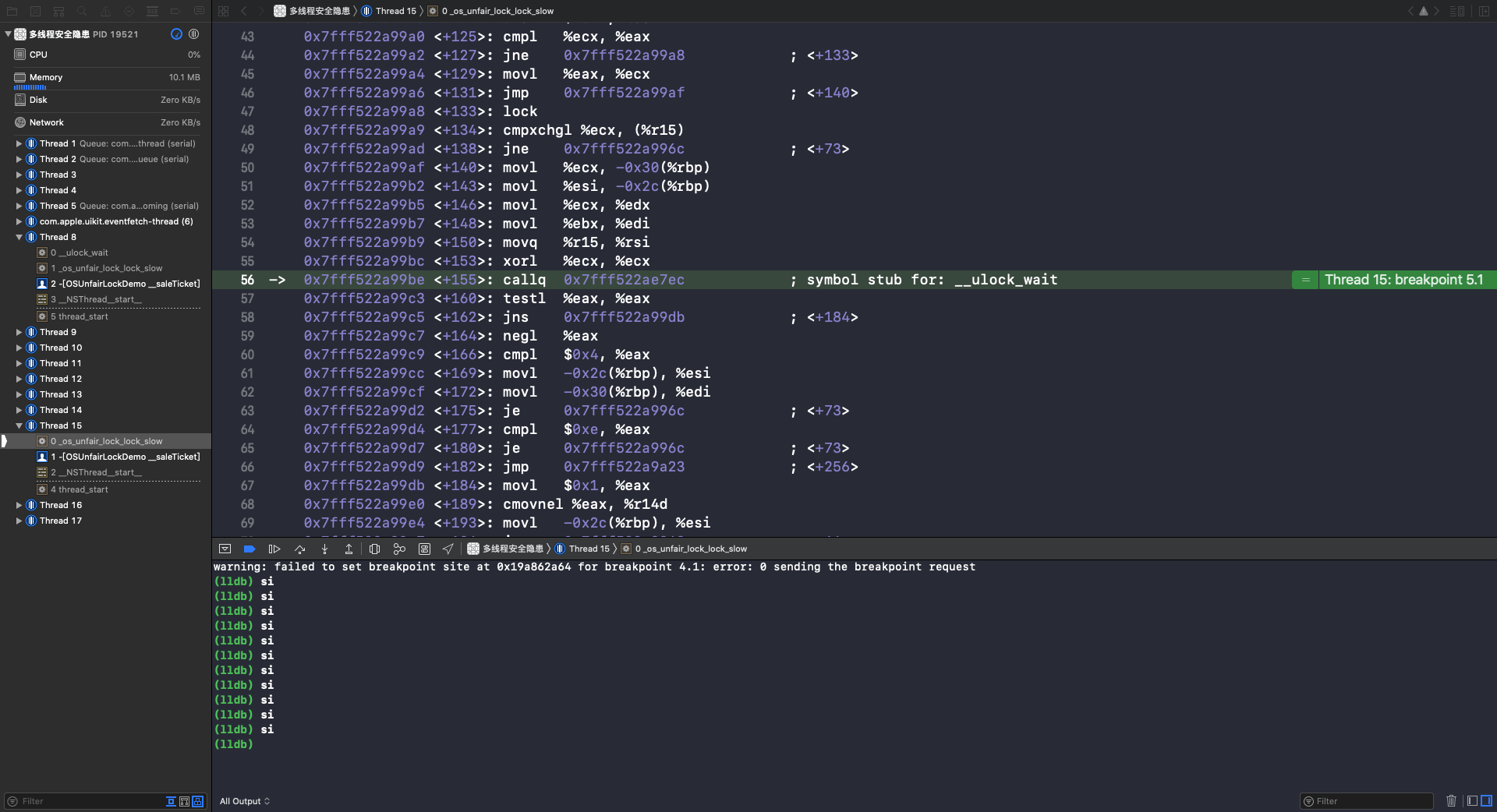
使用 si 指令,进入 __ulock_wait: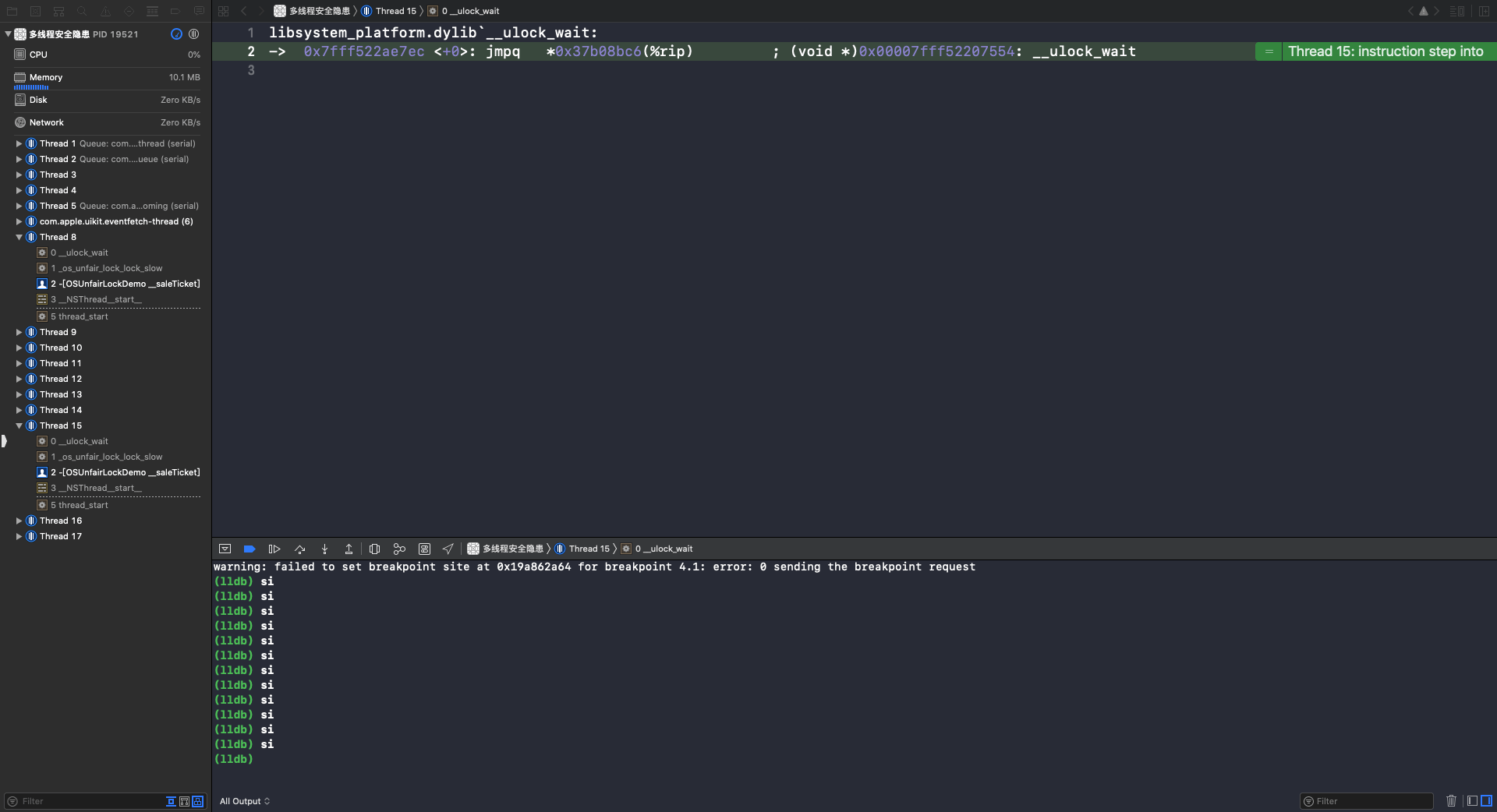
第4行 syscall 是系统调用,这个函数调用完成后,XCode 就又回到了OC代码页面,线程就进入休眠状态了(🔎 互斥锁标志):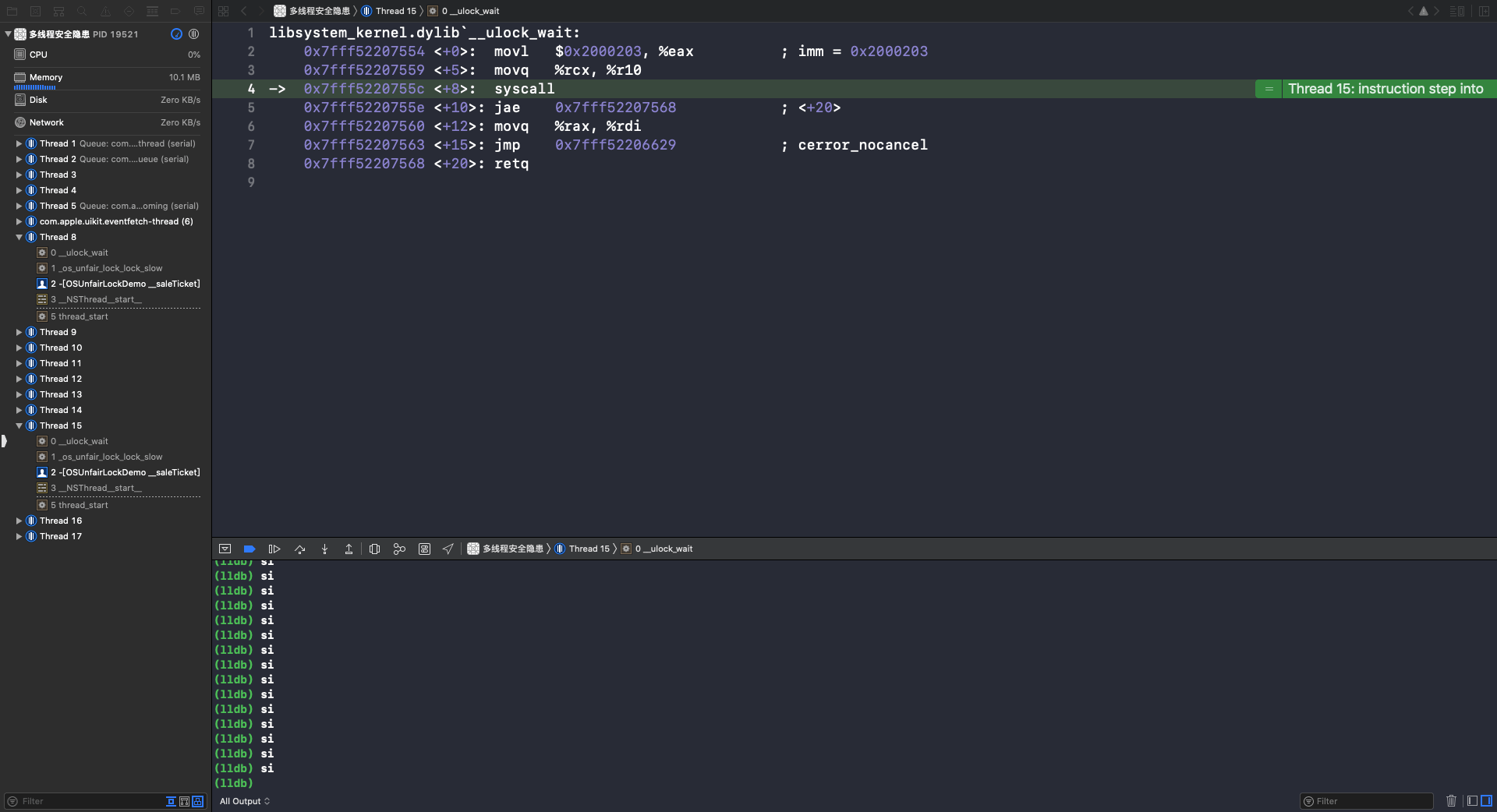
从上面👆对 os_unfair_lock 的汇编分析,可以看出 os_unfair_lock 是一个互斥锁。在 os_unfair_lock 的头文件 lock.h 里的注释可以看到一个单词 Low-level(低级锁),低级锁的特点就是休眠。自旋锁 OSSpinLock 是一个高级锁。
pthread_mutex
mutex 叫做”互斥锁”,等待锁的线程会处于休眠状态。需要导入头文件 #import <pthread.h>。
常用API
|
|
锁定类型:
PTHREAD_MUTEX_INITIALIZER
|
|
可以看到,PTHREAD_MUTEX_INITIALIZER 是一个结构体,在使用 PTHREAD_MUTEX_INITIALIZER 初始化锁时,由于结构体语法的问题,需要进行静态初始化:
如果使用 PTHREAD_MUTEX_INITIALIZER 动态初始化 pthread_mutex_t 会报错: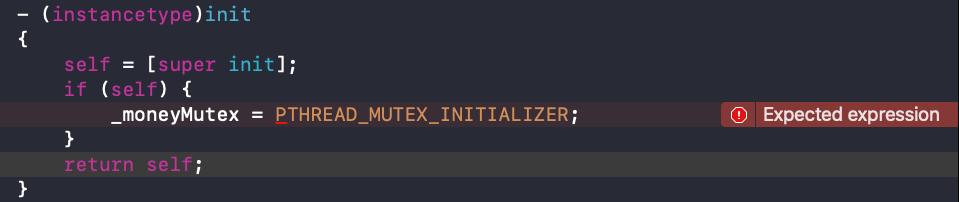
pthread_mutexattr_t
初始化 pthread_mutex 锁:
上面👆初始化锁的代码比较繁琐,一般使用 pthread_mutex_init(&_moneyMutex, NULL) 方法进行初始化。pthread_mutex_init() 方法的第二参数传 NULL,就相当于设置了 PTHREAD_MUTEX_DEFAULT 类型的 pthread_mutexattr_t 属性。
解决卖票和存钱取钱问题
定义 PthreadMutexDemo 继承自 LockBaseDemo。
打印结果同 OSSpinLock。
相对于 OSSpinLock 和 os_unfair_lock,pthread_mutex 的 API 里提供了销毁方法 pthread_mutex_destroy(),所以需要在 -(void)dealloc 方法里对锁进行销毁。
pthread_mutex 汇编分析
根据“查看汇编代码方法”查看 pthread_mutex 第二次尝试加锁的汇编代码。
可以看到第一次调用 - (void)__saleTicket 方法是在 Thread 10 并加锁。第二次调用 - (void)__saleTicket 方法是在 Thread 14,因为此时的自旋锁处于上锁状态,所以 Thread 14 处于等待锁的状态。重复执行 si 指令,到第11行时会调用 phread_mutex_lock 函数: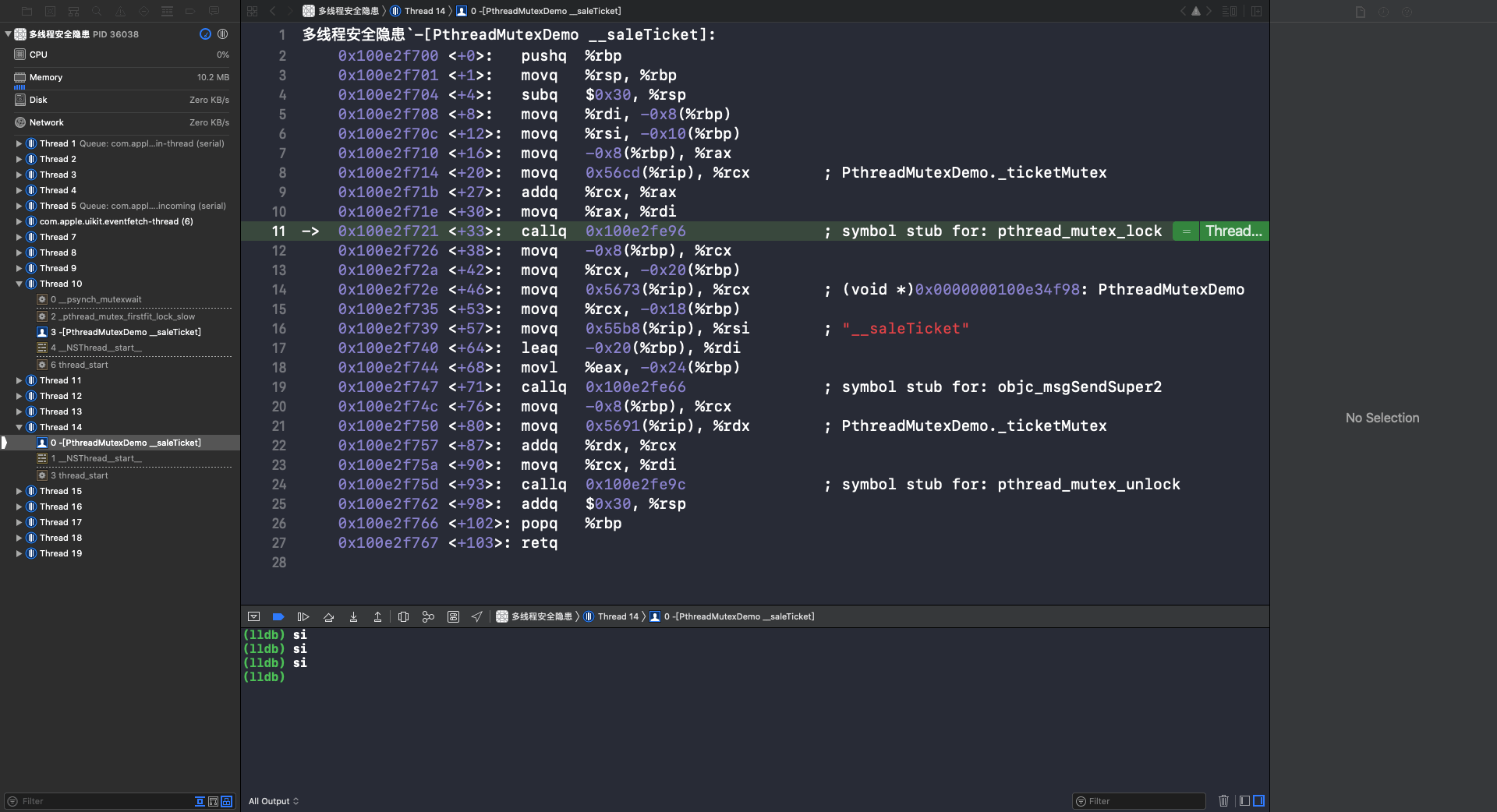
使用 si 指令进入到 phread_mutex_lock 函数: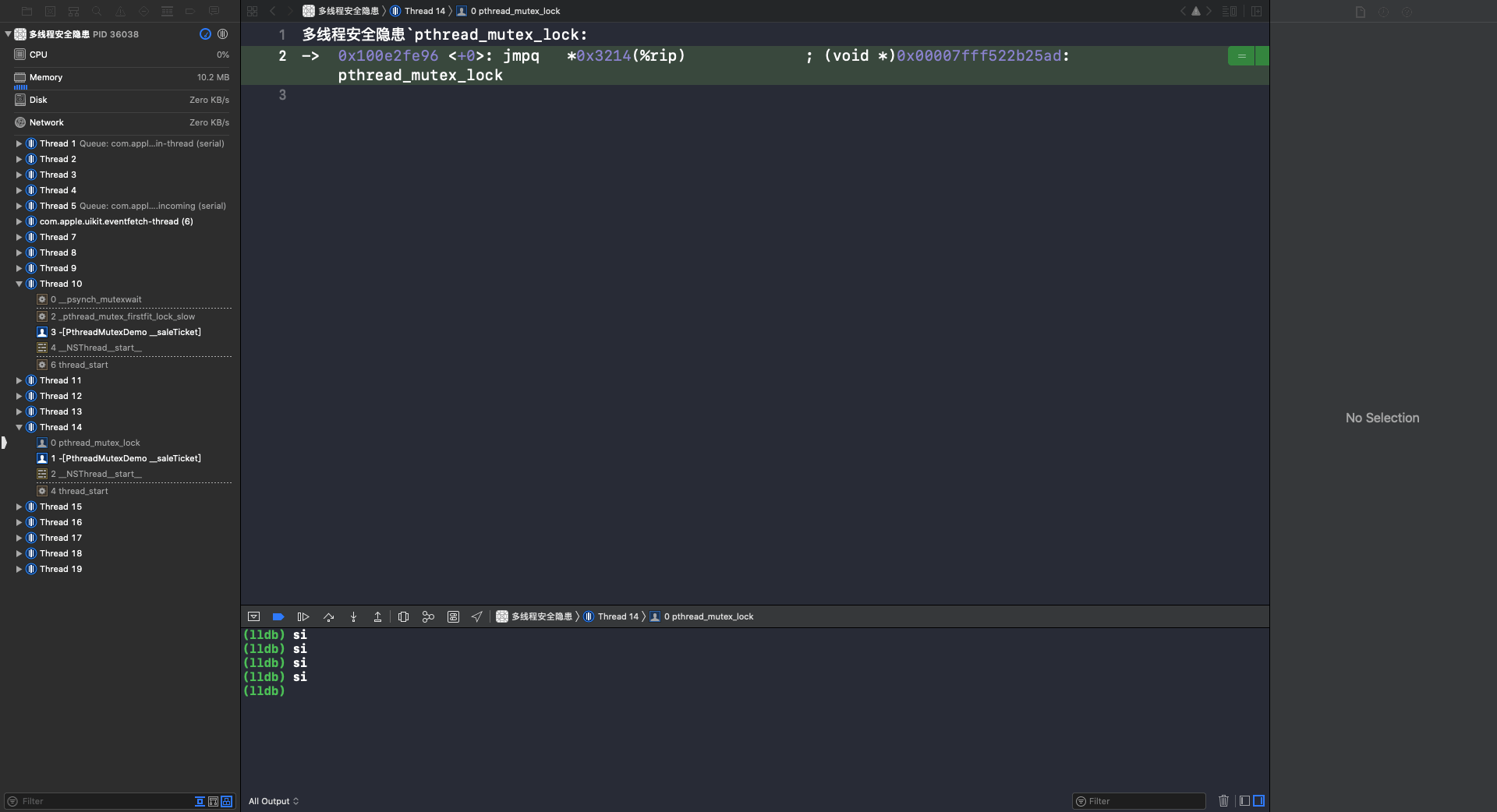
重复使用 si 指令,进入 _pthread_mutex_firstfit_lock_slow 函数: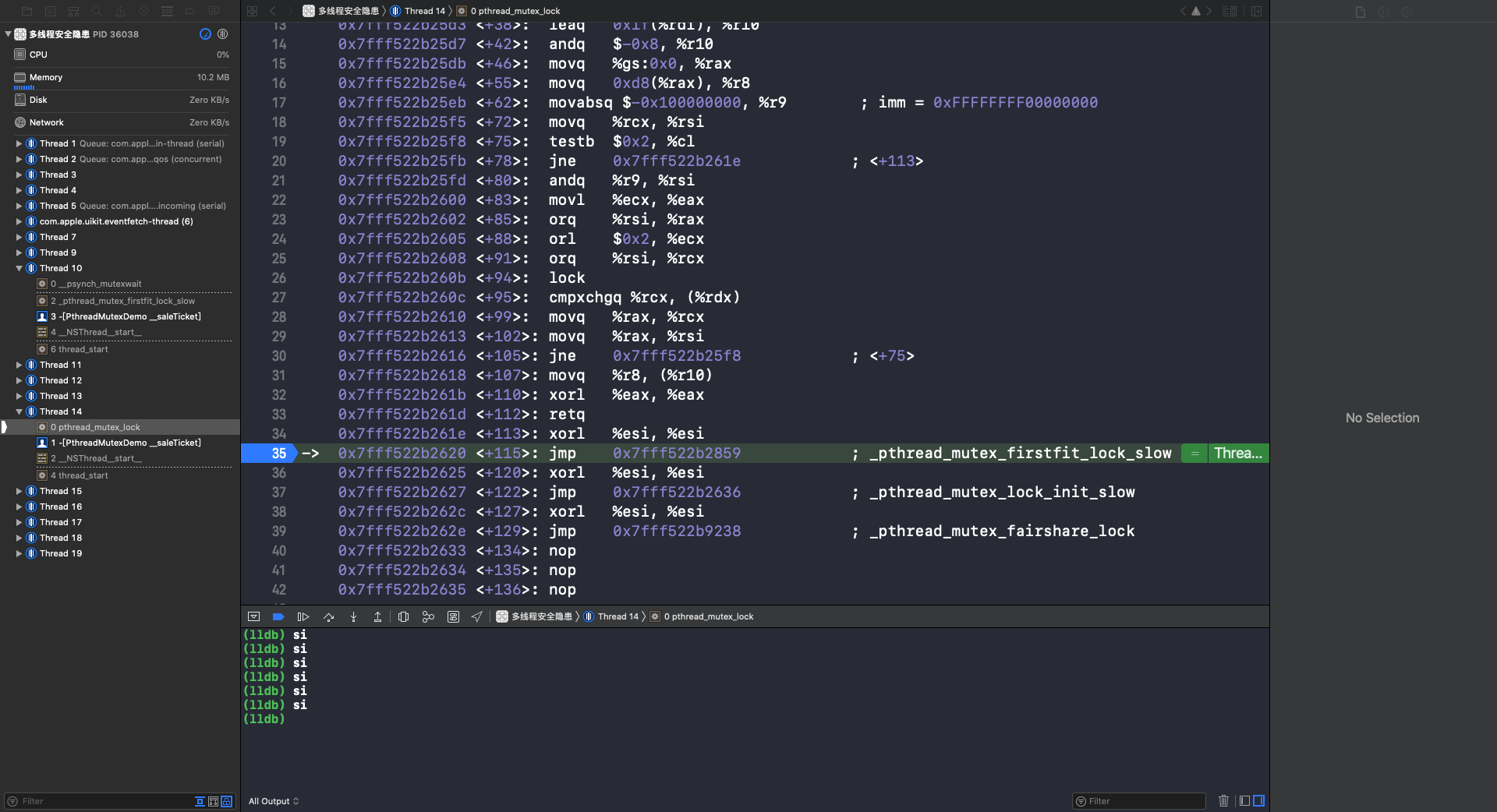
重复使用 si 指令,进入 _pthread_mutex_firstfit_lock_wait 函数: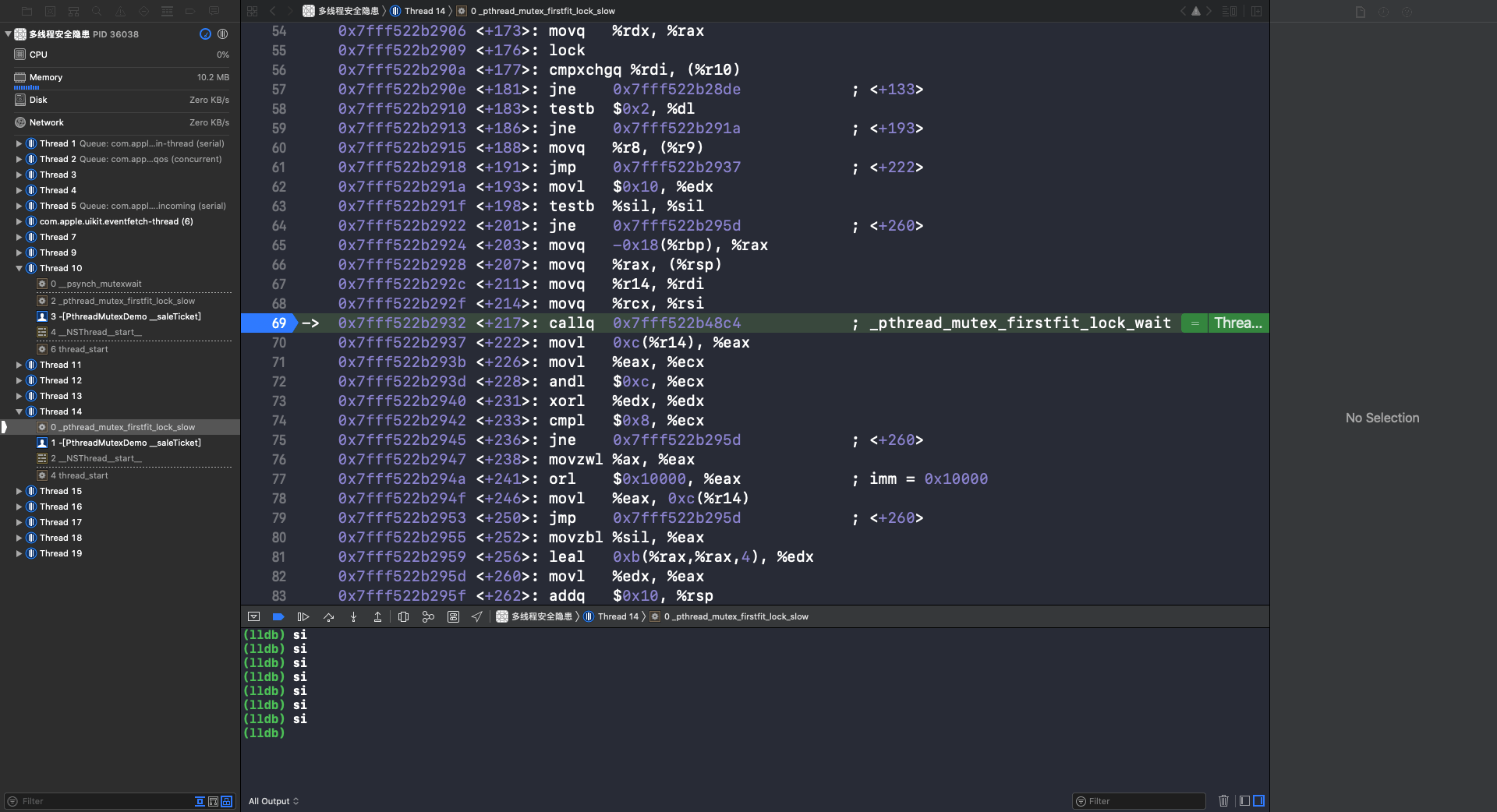
重复使用 si 指令,调用 __psynch_mutexwait: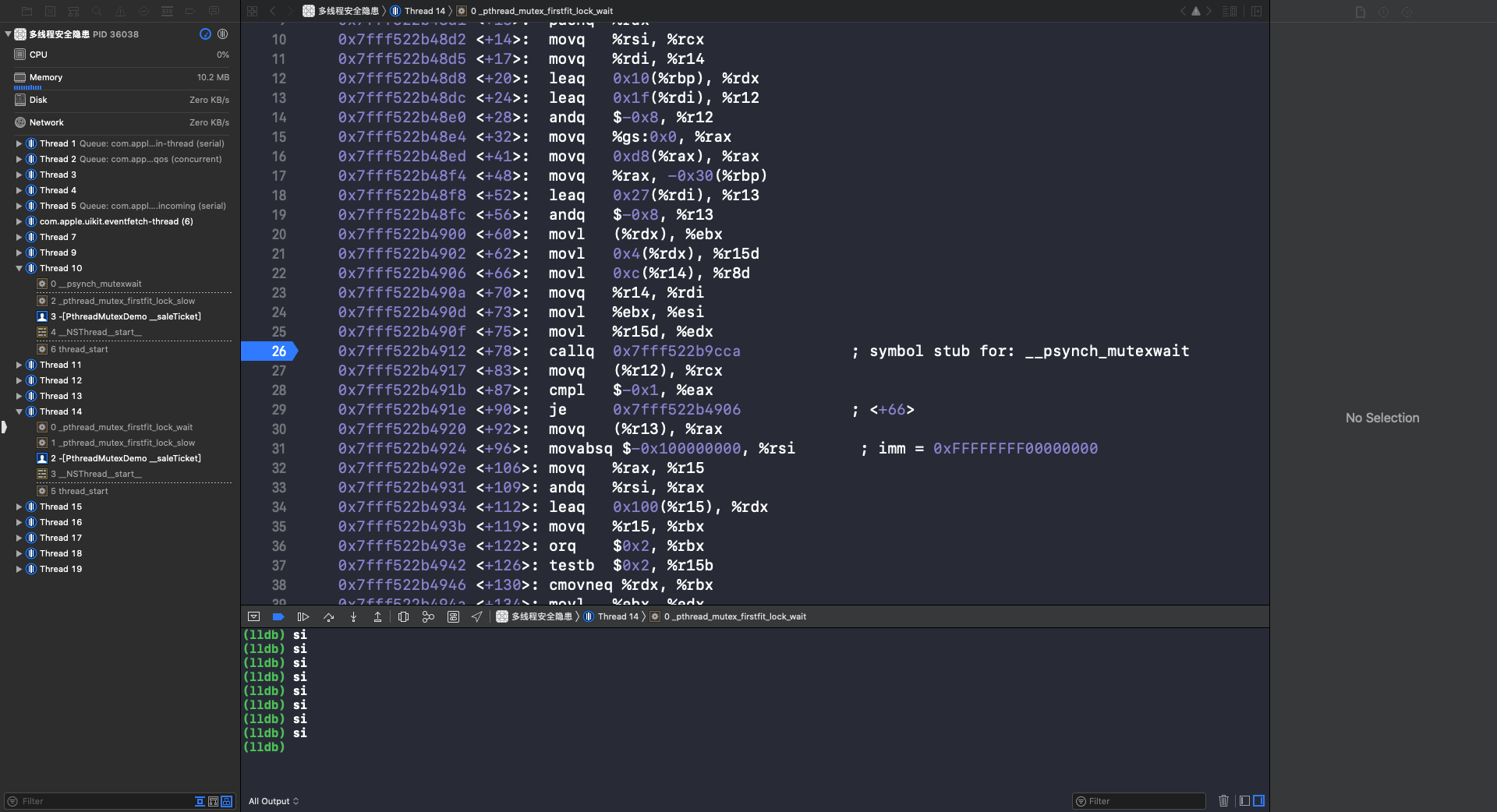
使用 si 指令,进入 __psynch_mutexwait 函数: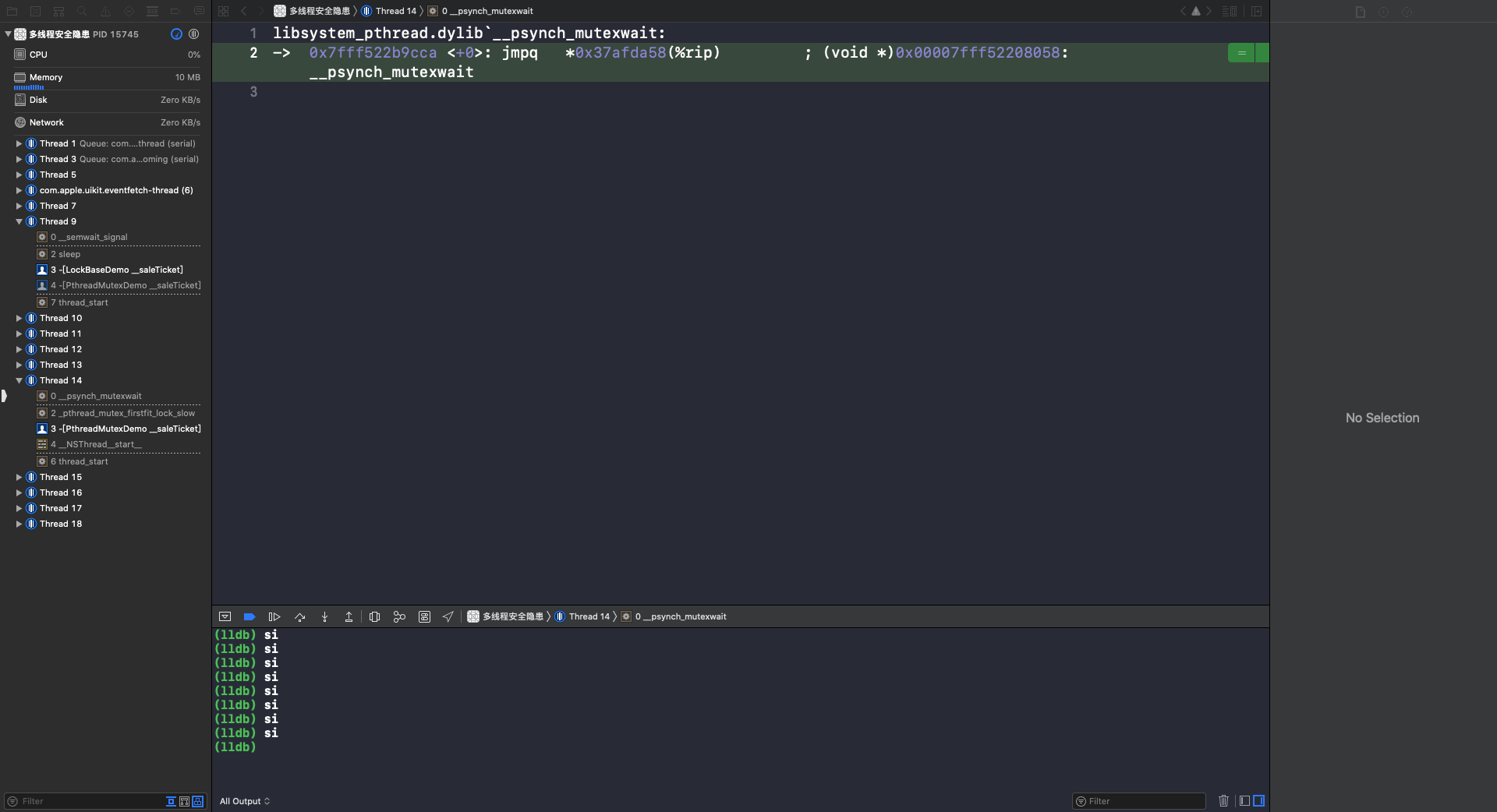
第4行 syscall 是系统调用,这个函数调用完成后,XCode 就又回到了OC代码页面,线程就进入休眠状态了(🔎互斥锁标志):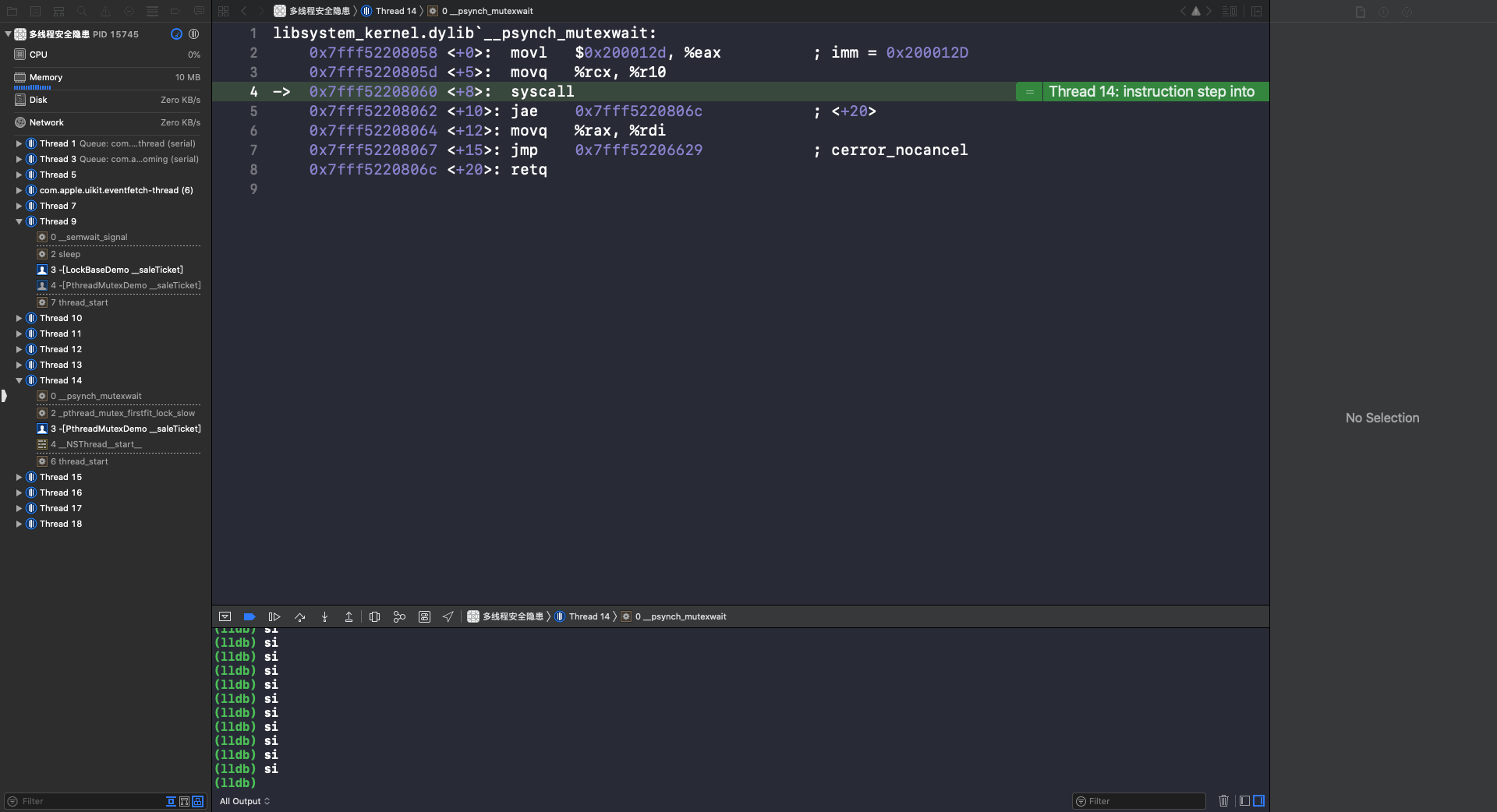
从上面👆对 pthread_mutex 的汇编分析,可以看出 pthread_mutex 是一个互斥锁,也是一个低级锁。
pthread_mutex – 递归锁
初始化 pthread_mutex 递归锁:
用 PTHREAD_MUTEX_RECURSIVE 类型定义的属性创建出来的 pthread_mutex 锁就是 pthread_mutex 递归锁。
死锁
在使用锁时如果出现了递归调用,或者在加锁后调用了一个使用同一把锁的方法,就会出现死锁的情况。与上面👆提到过的死锁的概念相同。
定义 PthreadMutexRecursiveDemo:
打印结果:
死锁情况一:递归调用
|
|
打印结果:
可以看到打印结果里只有一条打印信息,这是因为加锁后再次调用 -(void)recursiveMutexTest 方法,会发现 _mutex 已经上锁了,进入休眠等待解锁。
死锁情况二:函数间互相调用
|
|
打印结果:
可以看到打印结果里只有一条打印信息,这是因为两个方法使用的是同一把锁,在 - (void)recursiveMutexTest 方法加锁后再去调用 - (void)recursiveMutexTest2 方法时,会发现 _mutex 已经上锁了,进入休眠等待解锁。
递归锁
因为递归锁允许在同一个线程里重复加锁,所以递归锁可以解决上面出现的死锁情况。
解决死锁情况一:递归调用
|
|
打印结果:
解决死锁情况二:函数间互相调用
|
|
打印结果:
使用递归锁后,死锁的问题不存在了。但是,加了递归锁后的打印结果跟没加锁一样,这样被加锁的代码块还安全吗?其实,递归锁只可以在当前线程重复加锁。也就是说,当前线程加锁后,在当前线程再次调用 - (void)recursiveMutexTest 方法还可以重复加锁,而其它线程在此时调用 - (void)recursiveMutexTest 方法时判断到已经加过锁了就不再加锁了,会进入休眠等待解锁。
pthread_mutex – 条件
相关API
|
|
应用场景
|
|
打印结果:
在 pthread_cond_wait() 方法调用后,线程1会解锁并进入等待消息状态(休眠)。线程2监听到 pthread_mutex_t 锁已经解锁开始正常执行,添加完数据后发送消息。线程1在收到消息后会判断 pthread_mutex_t 锁是否已经上锁,如果已经上锁了就继续等待其解锁(休眠),一旦解锁了(线程2)就立即向下执行下面的代码。
因为应用场景是不同线程的调用,所以初始化属性时传入的第二个的参数 PTHREAD_MUTEX_RECURSIVE 也可以是 PTHREAD_MUTEX_NORMAL。
pthread_mutex 条件锁的应用场景比较少见,就算遇到了类似的场景,估计也不会选择用这种方式解决。它主要是解决优先及问题,上面👆代码中为了不对空数组进行删除操作,给锁添加了条件,保证了数组的删除操作在添加完数据后执行。
NSLock
NSLock 是对 mutex 普通锁的封装。
相关API
|
|
应用
|
|
打印结果同 OSSpinLock。
NSLock 实现原理
在 GNUstep 里的 source/Foundation 下面可以找到 NSLock.m 文件,在该文件里可以找到 NSLock 的具体实现:
NSRecursiveLock
NSRecursiveLock 是对 mutex 递归锁的封装,API 跟 NSLock 基本一致。
常用API
|
|
应用 - 递归调用
|
|
打印结果:
应用 - 方法间调用
|
|
打印结果:
NSRecursiveLock 实现原理
在 GNUstep 里的 source/Foundation 下面可以找到 NSLock.m 文件,在该文件里可以找到 NSRecursiveLock 的具体实现:
因为 NSRecursiveLock 是在 lock.m 文件定义的,所以 - (id)init 方法里的 attr_recursive 属性是在 + (void)initialize 方法👆里创建好的:
NSCondition
NSCondition 是对 mutex 和 cond 的封装。
相关API
|
|
应用
|
|
打印结果:
NSCondition 实现原理
在 GNUstep 里的 source/Foundation 下面可以找到 NSLock.m 文件,在该文件里可以找到 NSRecursiveLock 的具体实现:
NSConditionLock
NSConditionLock 是对 NSCondition 的进一步封装,可以设置具体的条件值。
相关API
|
|
应用
|
|
打印结果:
可以看到 NSConditionLock 可以给线程之间设置优先级。
如果使用 -(void)lock 方法只会判断锁是否处于加锁状态,如果不是就直接加锁,不会判断条件。
NSConditionLock 实现原理
在 GNUstep 里的 source/Foundation 下面可以找到 NSLock.m 文件,在该文件里可以找到 NSConditionLock 的具体实现:
dispatch_semaphore
semaphore 叫做“信号量”。信号量的初始值,可以用来控制线程并发访问的最大数量。信号量的初始值为1,代表同时只允许1条线程访问资源,保证线程同步。
相关API
|
|
应用 - 控制最大并发数量
|
|
打印结果:
从打印结果可以看到,一共执行了4次,每次5条线程。这是因为初始化 semaphore 的条件是5,每调用一次 dispatch_semaphore_wait 会减1,减5次等于0后就不在执行其它线程了。每调用一次 dispatch_semaphore_signal 会加1,就会有新的线程开始调用 dispatch_semaphore_wait 对条件减1。
应用 - 解决卖票和存钱取钱问题
|
|
打印结果同 OSSpinLock。
dispatch_semaphore 汇编分析
查看方式与 “OSSpinLock 汇编分析” 相同。可以看到第一次调用 - (void)__saleTicket 方法是在 Thread 9 对信号量减1。第二次调用 - (void)__saleTicket 方法是在 Thread 11,因为此时的信号量等于0,所以 Thread 15 处于等待信号量变成 >0 的状态。重复执行 si 指令,到第16行时会调用 dispatch_semaphore_wait 函数: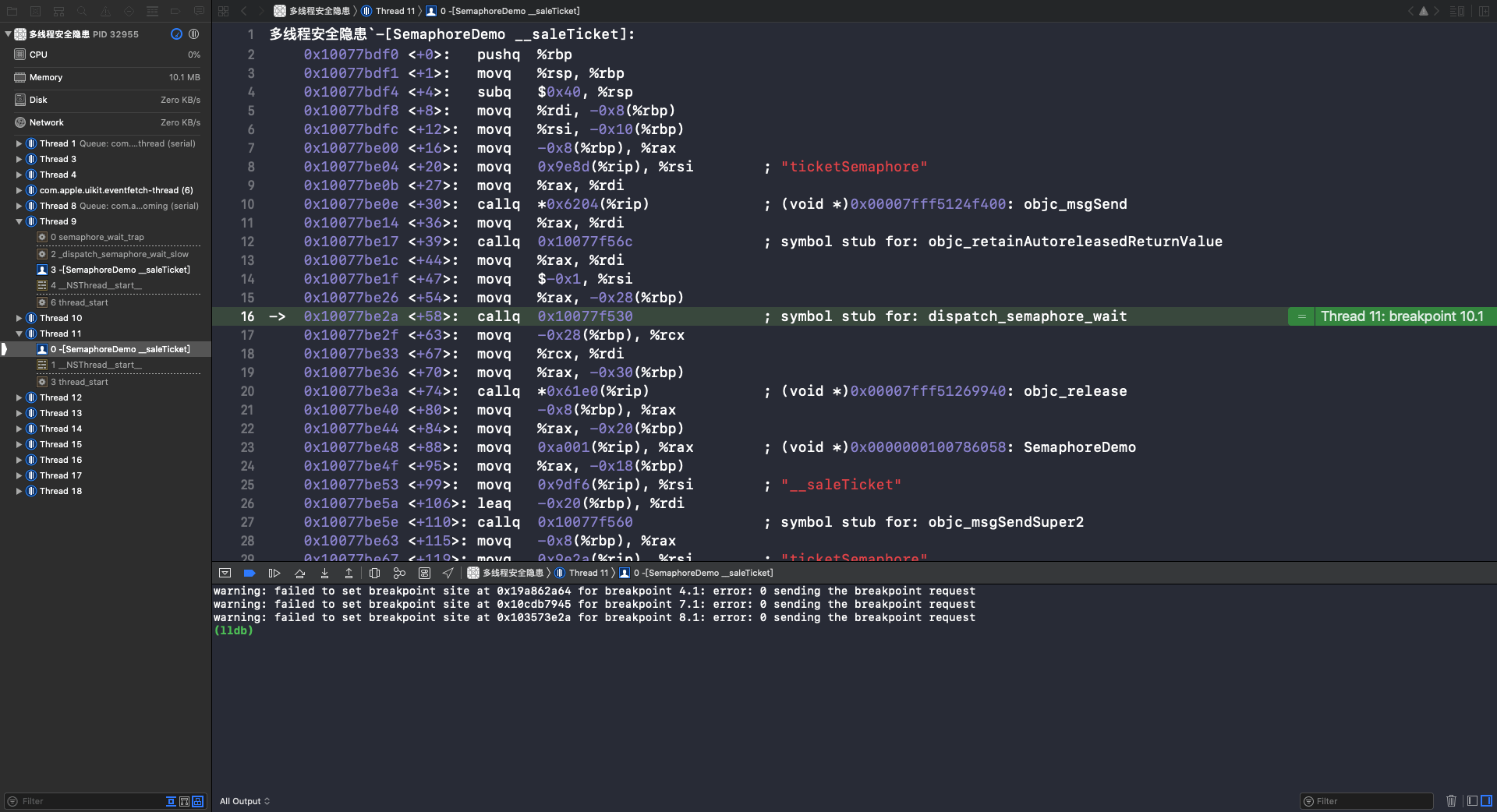
执行 si 指令,进入 dispatch_semaphore_wait 函数: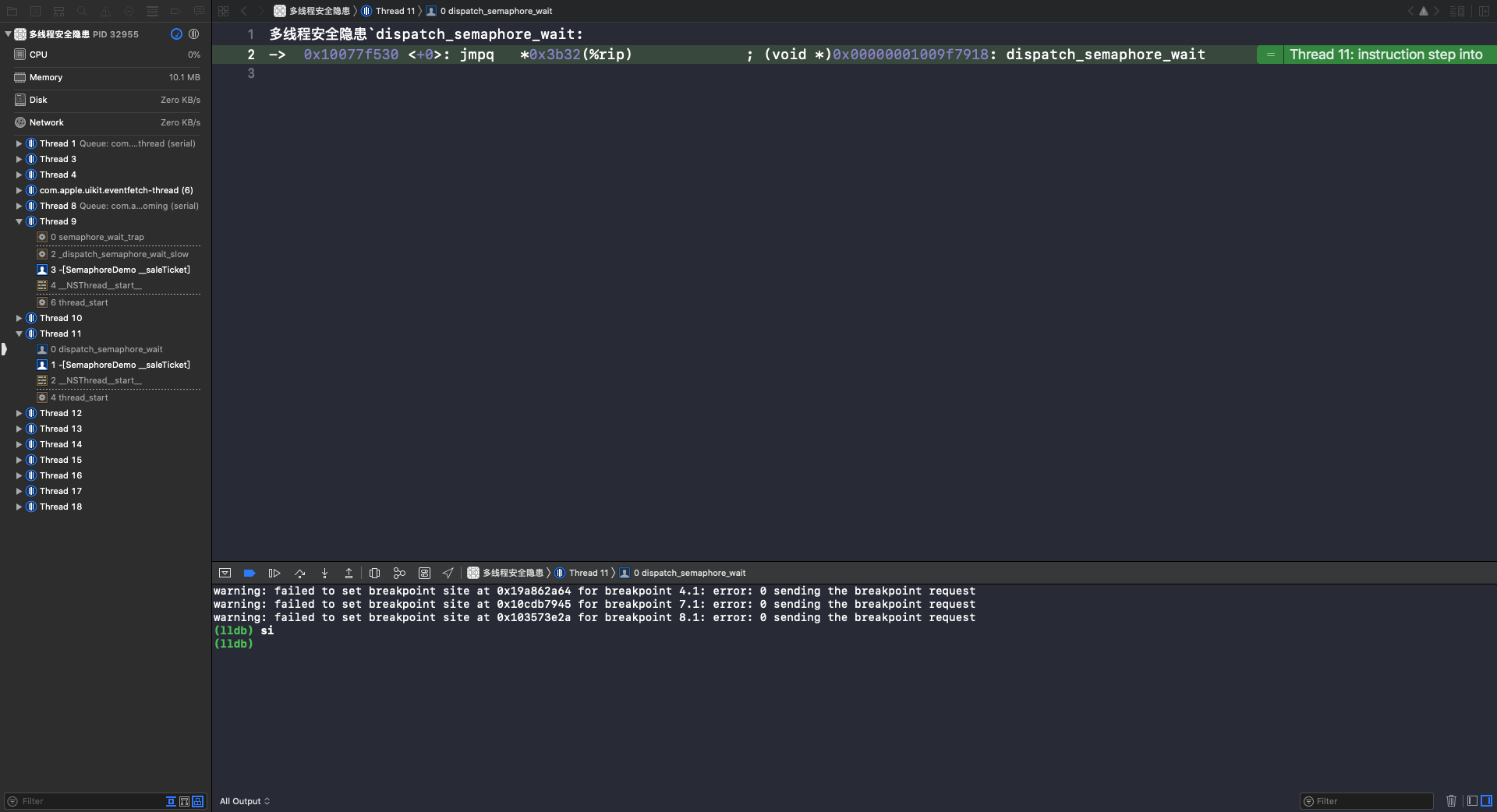
执行 si 指令,进入 dispatch_semaphore_wait_slow 函数: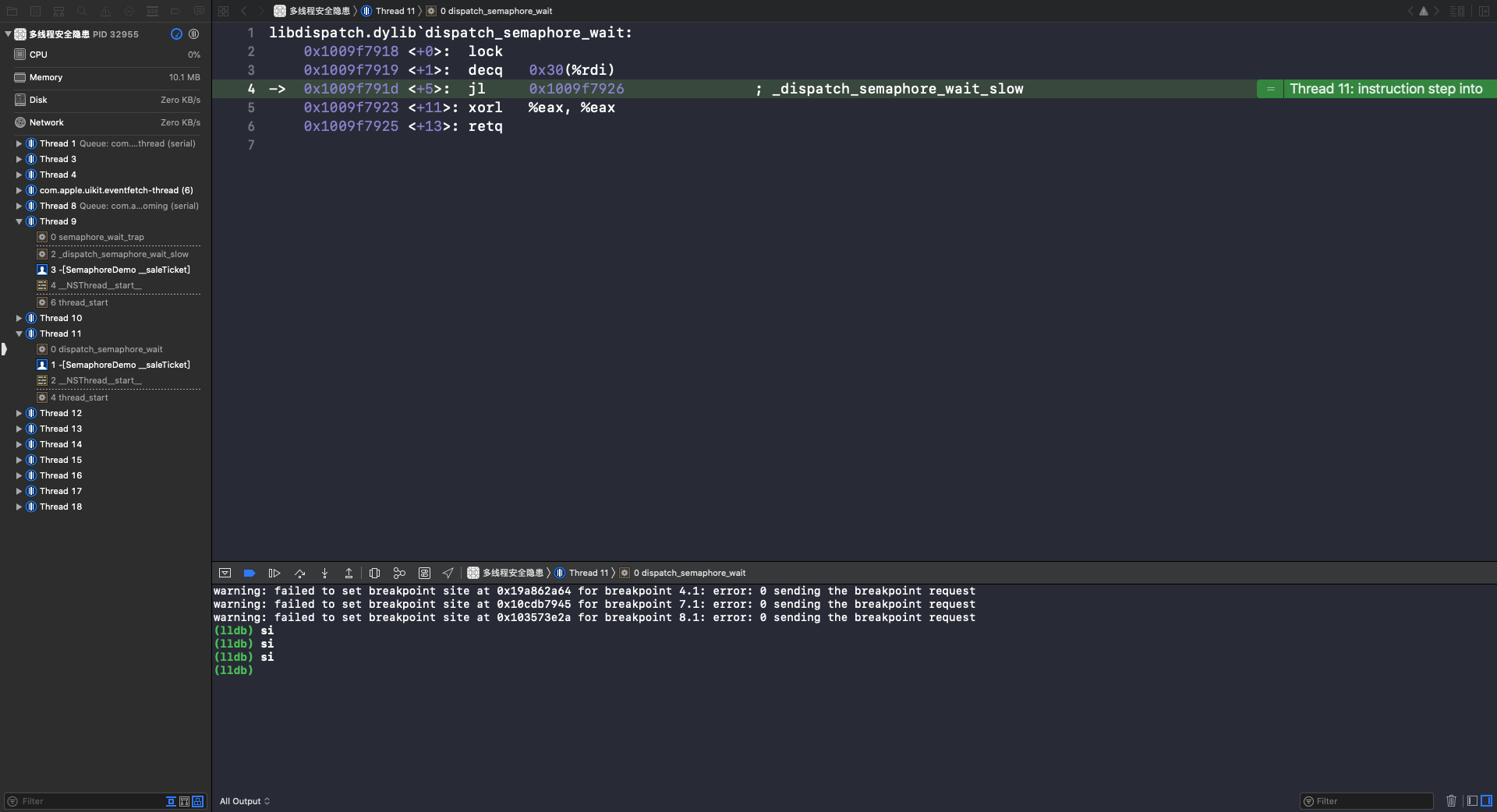
重复执行 si 指令,在第35行,进入 _dispatch_sema4_wait 函数: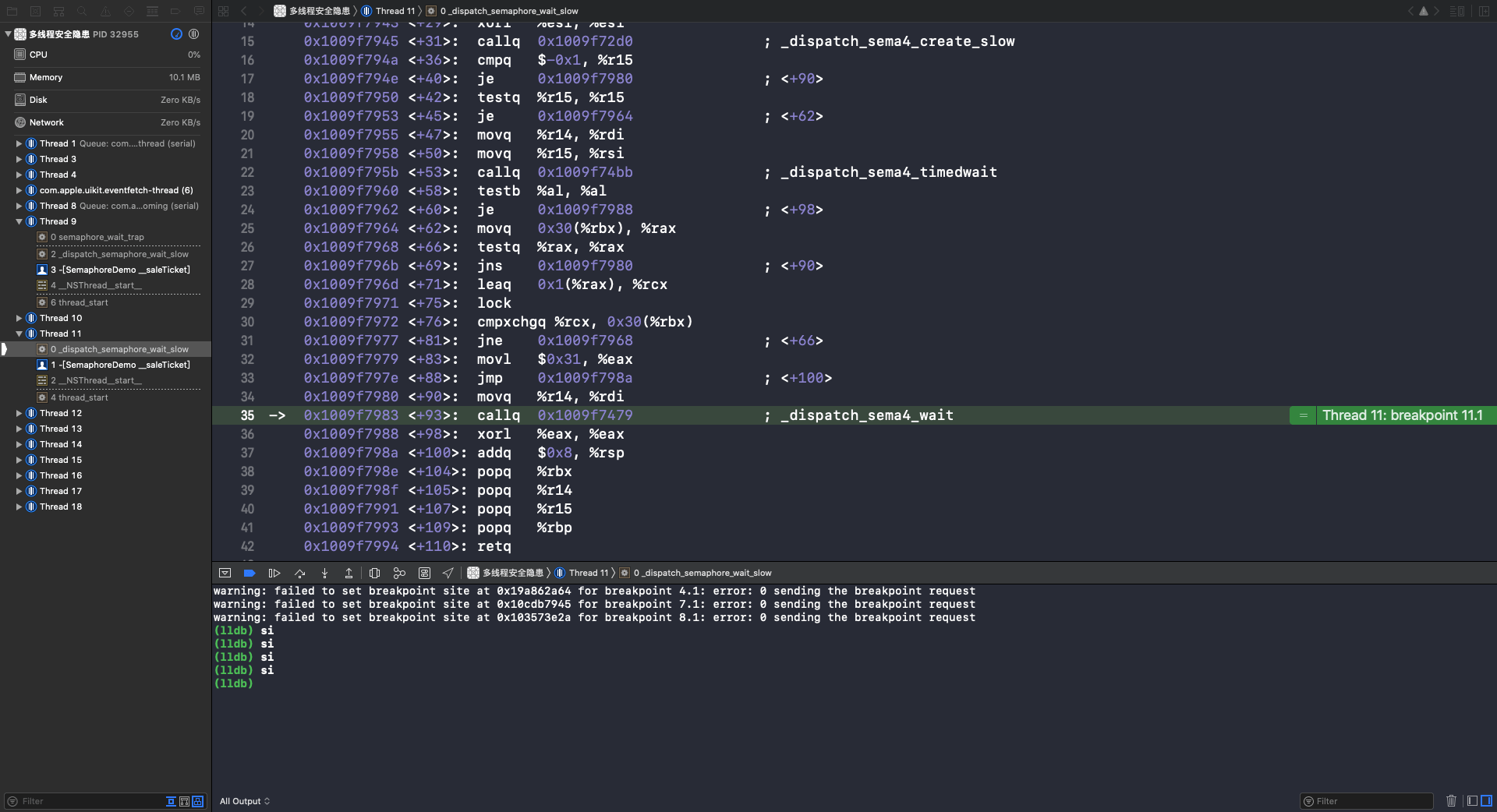
重复执行 si 指令,在第8行,调用 semaphore_wait 函数: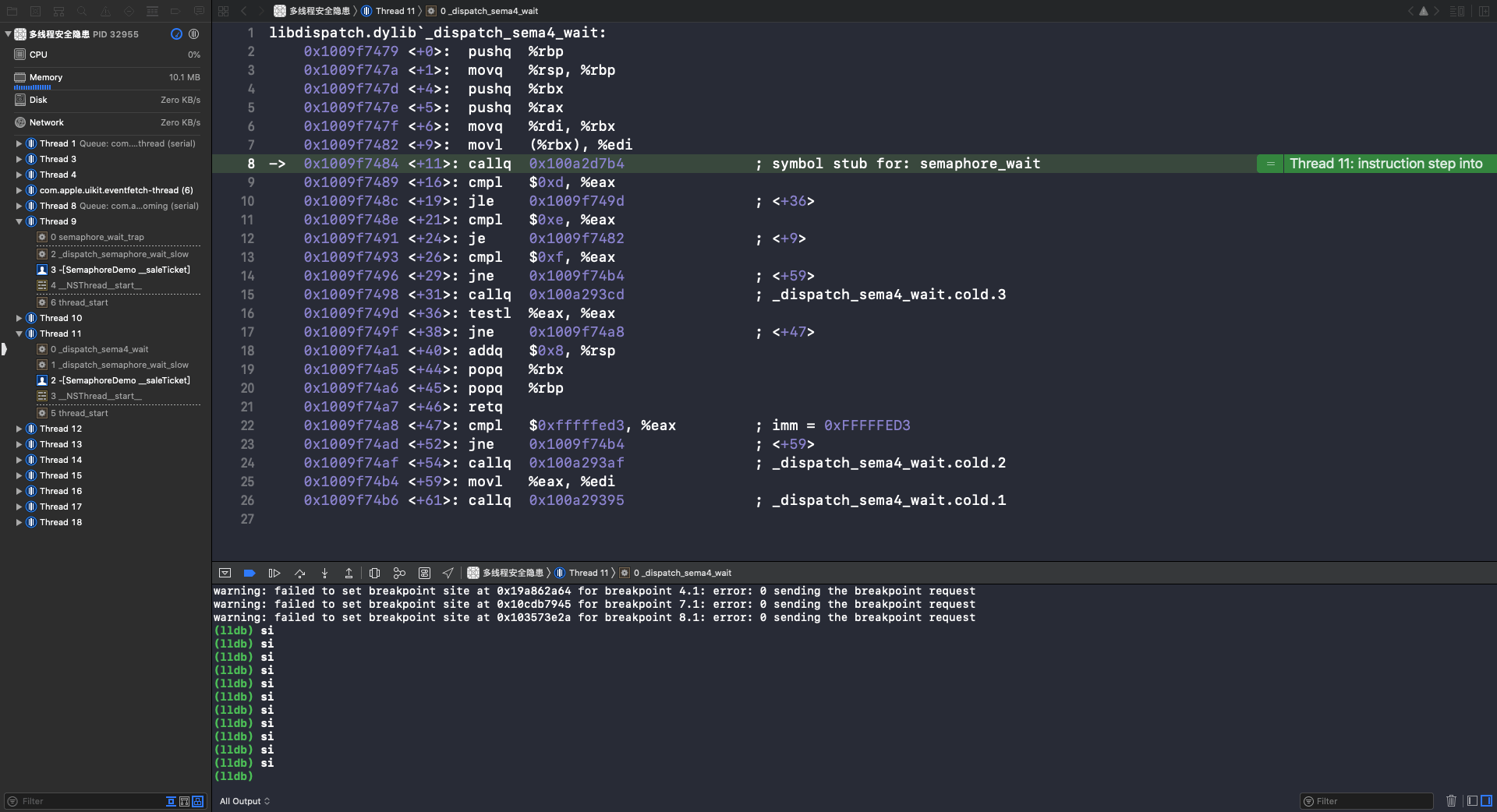
执行 si 指令,进入 semaphore_wait 函数: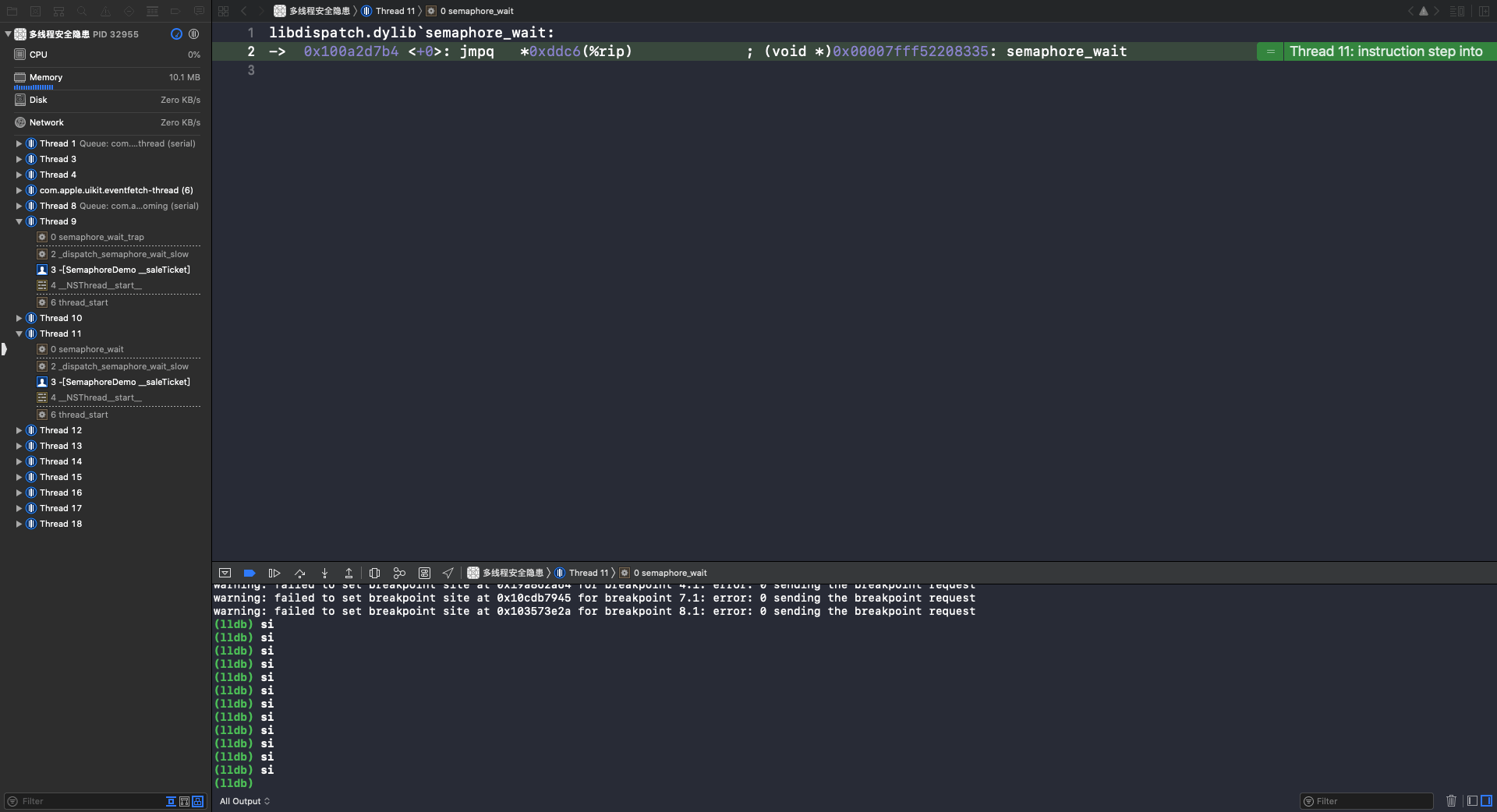
执行 si 指令,进入 semaphore_wait_trap 函数: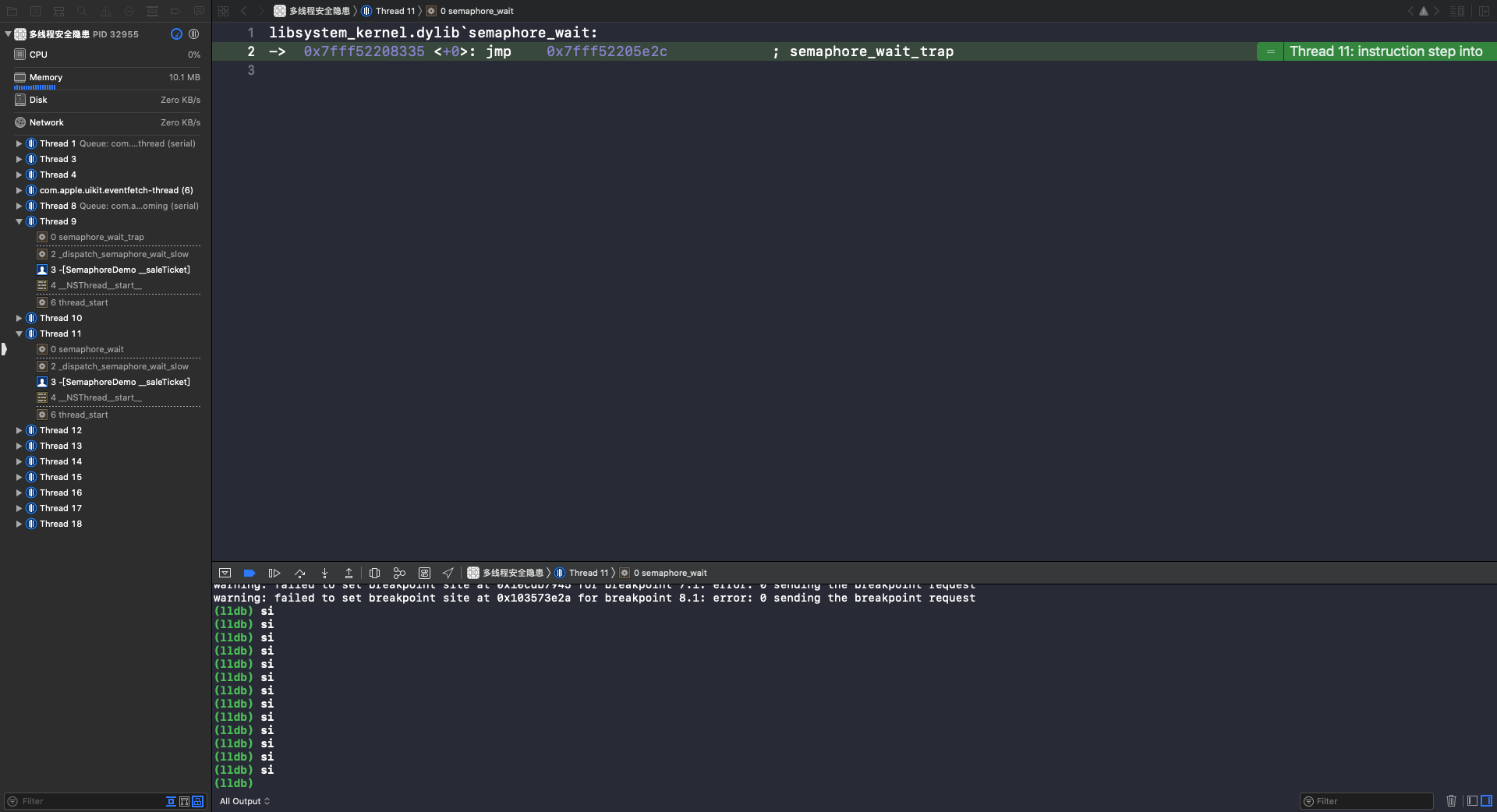
重复执行 si 指令,在第4行,调用 syscall 函数。syscall 是系统调用,这个函数调用完成后,XCode 就又回到了OC代码页面,线程就进入休眠状态了(🔎 互斥锁标志):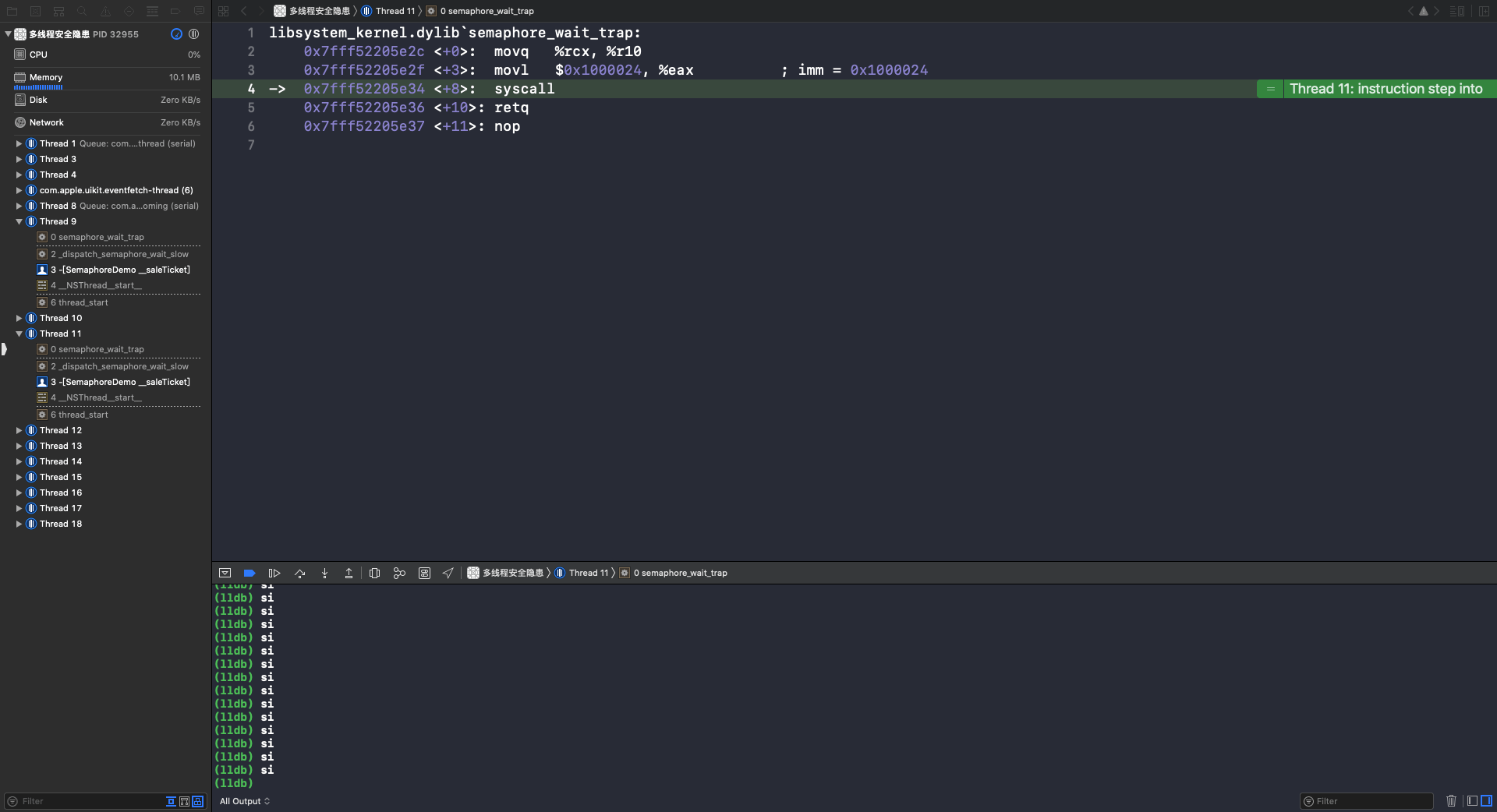
dispatch_queue
直接使用 GCD 的串行队列,也是可以实现线程同步的。因为线程同步的本质就是保证多条线程按顺序执行任务,所以串行队列可以通过控制执行顺序来实现线程同步。
解决卖票和存钱取钱问题:
打印结果同 OSSpinLock。
@synchronized
@synchronized 是对 mutex 递归锁的封装,@synchronized(obj) 内部会生成 obj 对应的递归锁,然后进行加锁、解锁操作。源码查看:objc4-781 中的 objc-sync.mm 文件。
解决卖票和存钱取钱问题
为了解决不同对象调用的问题,存钱取钱的 @synchronized() 传入的是类对象 [self class],卖票传入的是一个全局唯一的 NSObject 对象:
打印结果同 OSSpinLock。
@synchronized 实现原理
在断点1处查看汇编代码 Debug -> Debug Workflow -> Always Show Disassembly: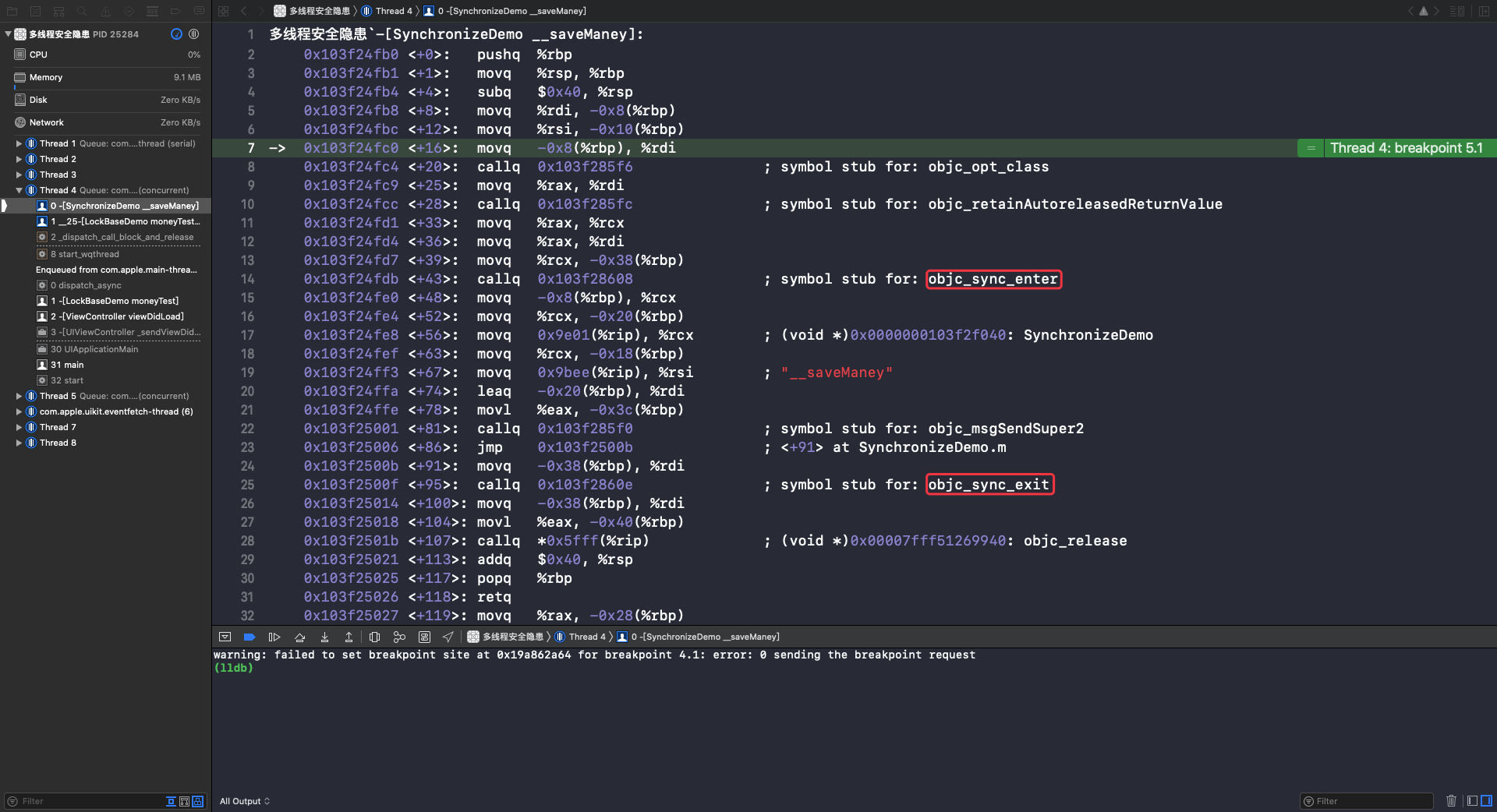
可以看到 @synchronized() 在开始和结束分别调用了 objc_sync_enter() 和 objc_sync_exit(),即:
源码查看:objc4-781 中的 objc-sync.mm 文件
SyncData 实现:
recursive_mutex_tt 实现:
因为从源码中看到锁在初始化时传入的是 OS_UNFAIR_RECURSIVE_LOCK_INIT,所以 @synchronized() 其实就是一个递归锁。
验证:
打印结果:
iOS线程同步方案性能比较
性能从高到低排序
- os_unfair_lock
- OSSpinLock
- dispatch_semaphore
- pthread_mutex
- dispatch_queue(DISPATCH_QUEUE_SERIAL)
- NSLock
- NSCondition
- pthread_mutex(recursive)
- NSRecursiveLock
- NSConditionLock
- @synchronized
推荐使用
- dispatch_semaphore
- pthread_mutex
dispatch_semaphore
不同方法使用 dispatch_semaphore 实现线程同步,每个方法都需要一把属于自己的锁,可以这样实现:
打印结果:
pthread_mutex
|
|
打印结果:
自旋锁、互斥锁比较
什么情况使用自旋锁比较划算?
预计线程等待锁的时间很短;(线程1加锁后处理的事情很少,线程2不需要等太多时间,就没必要去休眠,只通过一个while循环稍微等一下就好)
加锁的代码(临界区)经常被调用,但竞争情况很少发生;(对于多条线程同时调用临界区的情况很少,而且临界区的调用比较频繁,使用自旋锁效率会更高)
CPU资源不紧张;(自旋锁的优点是效率高,缺点是一直占用CPU资源,如果CPU资源不紧张,比如多核,就可以忽略自旋锁的缺点)
多核处理器;什么情况使用互斥锁比较划算?
预计线程等待锁的时间较长;(线程1加锁后处理的事情很多,比如需要耗时2~3秒,此时自旋锁效率高的优点也没啥用了,不如让线程2去休眠,这样也减少了CPU资源的占用)
单核处理器;(这种情况以节省CPU资源为主,尽量不去占用CPU资源)
临界区有IO操作;(因为IO操作是比较占用CPU资源的,所以这种情况以节省CPU资源为主)
临界区代码复杂或者循环量大;(因为这种情况比较耗时,所以忽略效率比较高的自旋锁,选择节省CPU资源的互斥锁)
临界区竞争非常激烈;(很多线程会同事调用临界区的代码,为了节省CPU资源,选择互斥锁)
atomic
atom:原子,不可再分割的单位。atomic:原子性,用于保证属性 setter、getter 的原子性操作,相当于在 getter 和 setter 内部加了线程同步的锁。
打开源码 objc4-781 的 objc-accessors.mm 文件,查看 setter 和 getter 方法 的实现:
aotmic 并不能保证使用属性的过程是线程安全的:
上面这段代码中 data 是原子性的,所以 self.data 是线程安全的,但是 addObject 不是线程安全的,需要单独加锁:
iOS中的读写安全方案
- 思考如何实现以下场景
同一时间,只能有1个线程进行写的操作;
同一时间,允许有多个线程进行读的操作;
同一时间,不允许既有写的操作,又有读的操作;
上面的场景就是典型的“多读单写”,经常用于文件等数据的读写操作,iOS中的实现方案有 pthread_rwlock(读写锁)和 dispatch_barrier_async(异步栅栏调用)。
pthread_rwlock
相关API:
|
|
应用
|
|
打印结果:
从打印结果可以看到,read 和 read 操作之间存在同时被打印的情况,但是 read 和 write 操作、write 和 write 操作之间不存在同时被打印的情况。
dispatch_barrier_async
这个函数传入的并发队列必须是自己通过 dispatch_queue_cretate 创建的,如果传入的是一个串行或是一个全局的并发队列,那这个函数便等同于 dispatch_async 函数的效果。
dispatch_barrier_async 方法能够保证当前只有这一个临界区在执行,就可以实现在写的时候,没有其它写操作和读操作。
相关API
|
|
应用
|
|
打印结果:
从打印结果可以看到,read 操作是可以同时进行的,write 操作只能一个一个执行。
总结
你理解的多线程?
通过多线程可以处理耗时任务,减少主线程的压力。
通过多线程可以处理一个复杂任务的不同部分,充分利用CPU资源,提升效率。
多线程意味着你能够在同一个应用程序中运行多个线程,多线程应用程序就像是具有多个 CPU 在同时执行应用程序的代码。其实这是一种假象,线程数量并不等于 CPU 数量,单个 CPU 将在多个线程之间共享 CPU 的时间片,在给定的时间片内执行每个线程之间的切换,每个线程也可以由不同的 CPU 执行。
iOS的多线程方案有哪几种?你更倾向于哪一种?
性能从高到低排序
os_unfair_lock
OSSpinLock
dispatch_semaphore
pthread_mutex
dispatch_queue(DISPATCH_QUEUE_SERIAL)
NSLock
NSCondition
pthread_mutex(recursive)
NSRecursiveLock
NSConditionLock
@synchronized
推荐使用
dispatch_semaphore
pthread_mutex
你在项目中用过 GCD 吗?
回到主线程
|
|
等所有的网络请求结束后,再刷新UI
|
|
延时执行
|
|
定时器
|
|
GCD 的队列类型
GCD的队列可以分为2大类型
并发队列(Concurrent Dispatch Queue)
可以让多个任务并发(同时)执行(自动开启多个线程同时执行任务);
并发功能只有在异步(dispatch_async)函数下才有效;串行队列(Serial Dispatch Queue)
让任务一个接着一个地执行(一个任务执行完毕后,再执行下一个任务);
主队列是一个特殊的串行队列,async 方法在主队列中添加任务不会开启新线程,并且是串行执行任务。
说一下 OperationQueue 和 GCD 的区别,以及各自的优势
OperationQueue 是对 GCD 的封装,更加面向对象。
GCD 相对于 OperationQueue 更加底层,效率更高。
线程安全的处理手段有哪些?
线程安全的处理是使用线程同步技术,包括加锁、信号量和串行队列。
OC你了解的锁有哪些?在你回答基础上进行二次提问;
性能从高到低排序:
os_unfair_lock
OSSpinLock
dispatch_semaphore
pthread_mutex
NSLock
NSCondition
pthread_mutex(recursive)
NSRecursiveLock
NSConditionLock
@synchronized
追问一:自旋和互斥对比?
什么情况使用自旋锁比较划算?
预计线程等待锁的时间很短;(线程1加锁后处理的事情很少,线程2不需要等太多时间,就没必要去休眠,只通过一个while循环稍微等一下就好)
加锁的代码(临界区)经常被调用,但竞争情况很少发生;(对于多条线程同时调用临界区的情况很少,而且临界区的调用比较频繁,使用自旋锁效率会更高)
CPU资源不紧张;(自旋锁的优点是效率高,缺点是一直占用CPU资源,如果CPU资源不紧张,比如多核,就可以忽略自旋锁的缺点)
多核处理器;什么情况使用互斥锁比较划算?
预计线程等待锁的时间较长;(线程1加锁后处理的事情很多,比如需要耗时2~3秒,此时自旋锁效率高的优点也没啥用了,不如让线程2去休眠,这样也减少了CPU资源的占用)
单核处理器;(这种情况以节省CPU资源为主,尽量不去占用CPU资源)
临界区有IO操作;(因为IO操作是比较占用CPU资源的,所以这种情况以节省CPU资源为主)
临界区代码复杂或者循环量大;(因为这种情况比较耗时,所以忽略效率比较高的自旋锁,选择节省CPU资源的互斥锁)
临界区竞争非常激烈;(很多线程会同事调用临界区的代码,为了节省CPU资源,选择互斥锁)
追问二:使用以上锁需要注意哪些?
加锁后一定要解锁;
一个变量对应一个锁;
使用 @synchronized(obj) 传入的 obj 对象就相当于一个锁,如果有不同的对象调用临界区,可以使用类对象 @synchronized([self class]);
在使用 pthread_mutex_t、pthread_mutex_t 递归锁、pthread_mutex_t 条件 和 pthread_rwlock_t 锁时需要手动释放。
追问三:用C/OC/C++,任选其一,实现自旋或互斥?
参考上面的内容。
请问下面代码的打印结果是什么?
|
|
上面有详解👆。
请问下面代码的打印结果是什么?
|
|
上面有详解👆。